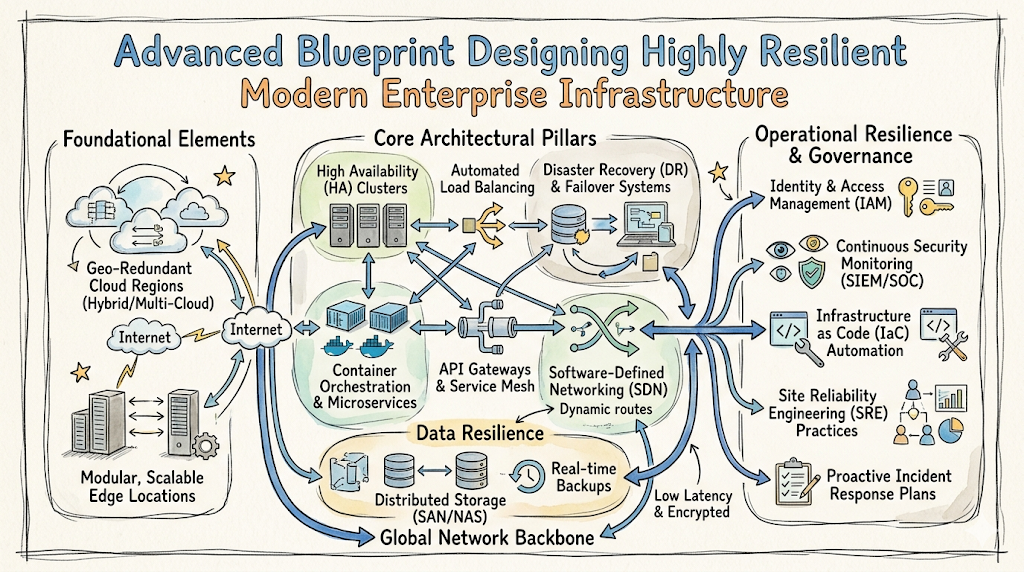
Introduction
Modern military operations—or WarOps—have evolved into a highly sophisticated domain combining advanced technology, strategic coordination, and rapid execution across physical and digital frontiers. This discipline applies rigorous engineering principles and multi-domain integration to ensure mission success under high-stakes conditions. By breaking down traditional, rigid command silos, it enables modern defense forces to maintain unprecedented speed, agility, and system resilience. To explore the tactical frameworks and technical breakdowns driving next-generation defense strategy, access the professional educational materials available at waropsx.com.
The Origin of Systems Infrastructure
The Early Industrial Bottlenecks
Historically, organizations treated software development and infrastructure management as entirely separate, isolated functions. Developers focused exclusively on pushing out new features as fast as possible, while operations teams shouldered the burden of maintaining stability.
This deep division created a highly adversarial environment where code changes were thrown over a metaphorical wall. Operations teams, lacking context on how the software was built, naturally resisted updates to prevent system instability.
Because communication channels were closed, diagnosing a failure in production required hours of finger-pointing and guesswork. This structural fragmentation meant that deployments were rare, stressful, and highly prone to catastrophic human error.
Moving Toward Unified Workflow Automation
As commercial digital platforms transitioned to the cloud, this old, fragmented approach became completely unsustainable. Organizations realized they needed a unified workflow that bridged the gap between code creation and stable long-term execution.
This realization sparked a movement centered on shared responsibility, continuous integration, and rapid feedback loops. Engineering teams began writing code to manage physical infrastructure, treating hardware configurations with the same rigor as application software.
By automating the delivery pipeline, companies successfully removed the human bottlenecks that previously choked speed and reliability. This fundamental evolution transformed infrastructure management from a manual, defensive chore into a high-velocity strategic advantage.
Global Expansion Across Commercial Ecosystems
What began as an internal cultural shift within a few cutting-edge internet pioneers quickly expanded into a global standard. As traditional enterprises watched digital-native companies disrupt mature markets, they recognized that operational velocity was a matter of survival.
Major financial institutions, global retail giants, and massive healthcare networks all began adopting these modern systems frameworks. They re-engineered their internal systems, shifting away from massive, fragile monolithic applications toward flexible, distributed cloud architectures.
Today, this unified methodology is no longer a luxury reserved for elite tech hubs. It serves as the standard operational backbone for any business that relies on high-availability software to serve millions of global users.
Defining Strategic Operations Management
The Core Operational Structure
At its absolute foundation, modern operations management treats infrastructure problems as fundamentally software engineering problems. Instead of relying on manual interventions, the operational architecture treats every server, network link, and database as code.
Information flows continuously through automated loops, where telemetry data feeds directly back into self-healing software scripts. This layout ensures that whenever a component deviates from its optimal baseline, the system automatically attempts to remediate itself.
By applying strict engineering principles to live operational environments, organizations create highly predictable, observable, and scalable systems. This structural design turns chaotic, unpredictable infrastructure into an orderly, programmatic pipeline.
Daily Tasks of Systems Coordinators
Systems coordinators spend their days balancing live operational maintenance with active software development. They do not sit around waiting for things to break; instead, they build automated tools to ensure systems cannot break in the first place.
A coordinator might spend their morning writing scripts to automate multi-region cluster deployments, and their afternoon analyzing performance metrics to find hidden latency spikes. They also participate in architecture design reviews, ensuring that new features are built to scale safely from day one.
When live incidents do occur, these specialists act as technical first responders, diagnosing root causes quickly using advanced telemetry. Their primary objective is always to ensure that any manual fix applied today is fully automated away tomorrow.
Localized Control vs. Broad System Architecture
Managing modern infrastructure requires balancing granular control over specific components with a holistic understanding of the entire multi-system architecture. Localized control focuses on optimizing individual microservices, ensuring single databases perform at peak efficiency.
However, looking only at local components can blind teams to complex cascading failures that ripple across an entire distributed network. Broad system architecture takes a macro view, mapping out how hundreds of individual services interact, communicate, and fail together.
Operational excellence requires shifting seamlessly between these two viewpoints. Specialists must understand how a tiny change in a localized configuration file might impact the global throughput of the entire enterprise ecosystem.
The Efficiency Mindset
The true defining characteristic of a world-class operations team is a deep, culturally ingrained commitment to long-term system reliability. This mindset rejects quick, temporary fixes that simply mask underlying architectural flaws.
Instead of patching a failing server manually, an efficiency-minded engineer tears the server down and rewrites the deployment script to prevent the failure from ever returning. This philosophy requires accepting that system failure is an inevitable part of operating complex distributed systems at scale.
Because they assume failures will happen, teams design systems to fail gracefully without disrupting the end-user experience. This relentless focus on proactive resilience reduces operational stress and allows organizations to innovate with absolute confidence.
The 7 Core Principles of Introduction to Modern Military Operations – WarOpsX.com
1. Embracing Risk and Managing Variability
Perfect uptime is a dangerous myth that stalls corporate innovation and rapidly burns out engineering talent. Modern operational theory accepts that physical components will degrade, networks will drop packets, and software will contain hidden bugs.
Instead of chasing an impossible goal of zero failure, teams focus on defining and managing an acceptable level of systemic risk. This approach allows organizations to move fast and deploy new features, knowing they have a calculated safety buffer in place.
By embracing risk mathematically, teams stop wasting massive financial resources trying to over-engineer systems for unrealistic reliability targets. They focus their energy on making sure the system can handle variability without causing widespread user disruption.
2. Establishing Service Level Objectives (SLOs)
You cannot manage or optimize what you do not accurately measure. Teams must establish clear, quantitative targets for system performance, known formally as Service Level Objectives.
These objectives are built directly around user happiness, measuring critical metrics like successful request percentages or acceptable data delivery speeds. By defining these targets explicitly, both business stakeholders and engineering teams align on exactly what constitutes acceptable performance.
These metrics act as a definitive truth source, removing emotional arguments from operational decisions. When a system meets its objectives, developers are free to innovate; if it falls short, the focus shifts entirely to stabilizing infrastructure.
3. Eliminating Toil and Manual Processes
Toil is the repetitive, predictable, manual operational work that scales linearly with the size of a system but adds no long-term strategic value. Examples include manually resetting stuck application servers, manually creating user accounts, or performing routine database backups by hand.
Left unchecked, toil acts as a silent killer of productivity, burying engineers under a mountain of administrative maintenance. Modern operational principles dictate that teams must aggressively identify this manual work and use engineering hours to script it away.
The goal is to keep toil below a strict percentage of an engineer’s work week, usually capped at fifty percent. This restriction ensures that specialists always have dedicated time to focus on creative, high-value architecture scaling projects.
4. Monitoring & Observability Across the Pipeline
Traditional monitoring merely tells you when a system has completely broken down by triggering a basic alert after a threshold is crossed. Modern observability goes much deeper, providing complete, granular visibility into the internal states of an entire pipeline based on external outputs.
By collecting logs, metrics, and distributed traces across every single infrastructure layer, teams can easily pinpoint the exact root cause of complex, hidden anomalies. This continuous visibility ensures that engineers spot subtle performance degradations long before they turn into major outages.
A fully observable pipeline allows teams to ask complex, un-predetermined questions about system behavior during live events. This deep insight transforms troubleshooting from a game of guessing into a precise, data-driven science.
5. Automation Over Manual Coordination
Human beings are slow, inconsistent, and highly prone to mistakes when performing repetitive, high-stress tasks under pressure. Therefore, modern systems management prioritizes smart software automation over manual human coordination at every single opportunity.
Whether provisioning thousands of new cloud nodes, updating firewall rules, or routing traffic away from data centers, software scripts execute these actions perfectly every time. This automation allows modern infrastructure to scale up or down smoothly in response to real-time consumer demand fluctuations.
By removing human intervention from the core deployment loop, teams eliminate the typos and misconfigurations that cause the vast majority of production outages. Engineers focus on designing the automation rules, while software handles the heavy lifting of day-to-day execution.
6. Release Engineering and Deployment Stability
Shipping code from a developer’s laptop to a live production environment must be a boring, highly predictable, and completely repeatable process. Release engineering treats the deployment pipeline as a core product that requires continuous optimization, automated testing, and strict version control.
Teams utilize advanced deployment strategies like canary releases or blue-green deployments to minimize the blast radius of new updates. These methods allow organizations to test new code on a tiny fraction of live traffic before rolling it out globally.
If an unexpected bug shows up during a rollout, automated systems immediately detect the regression and trigger an instantaneous, safe rollback. This disciplined approach ensures that feature delivery never comes at the cost of overall system stability.
7. Simplicity in Network Architecture
Complexity is the absolute worst enemy of system reliability and long-term infrastructure security. As environments grow, there is a natural, dangerous tendency to add custom configurations, nested layers, and specialized workarounds.
Modern operations principles push back hard against this bloat, advocating for absolute simplicity and minimalism in network architecture. Standardized components, clean communication interfaces, and uniform environmental setups make systems far easier to understand, maintain, and troubleshoot.
By keeping infrastructure minimal, teams significantly reduce the overall surface area where failures can occur. A clean, simple architecture ensures that when a component behaves abnormally, engineers can quickly trace the path of execution and resolve the problem.
Key Operational Concepts You Must Know
SLA vs. SLO vs. SLI — Explained Simply
Understanding the relationship between SLAs, SLOs, and SLIs is absolutely essential for managing modern infrastructure effectively. These three metrics form the core framework used to measure operational success and keep engineering teams aligned with business goals.
- SLI (Service Level Indicator): This is the precise quantitative measure of a system’s performance in real-time. Common examples include the exact percentage of successful HTTP requests or the exact latency of a database query measured in milliseconds.
- SLO (Service Level Objective): This is the target metric or range of metrics where you want your SLIs to live. For instance, a team might set an objective stating that their database latency SLI must remain under two hundred milliseconds for ninety-nine percent of all requests over a rolling thirty-day period.
- SLA (Service Level Agreement): This is the high-level, formal commitment made to external customers regarding overall system performance. It explicitly includes the financial or legal penalties, such as service credits or contract refunds, that occur if the system fails to meet its stated SLOs.
Error Budgets — The Game Changer for Operational Risk
An error budget is the exact mathematical inverse of a system’s Service Level Objective, representing the maximum allowable downtime or performance degradation over a specific timeframe. For example, if your team commits to a ninety-nine percent availability SLO, your system has a calculated error budget of exactly one percent.
This framework acts as a clear, objective buffer that balances rapid feature innovation with baseline system safety. Developers spend this error budget whenever they deploy new features, alter infrastructure configurations, or run experimental code in production.
If a series of outages completely consumes the error budget before the tracking period ends, all new feature releases are instantly frozen. The entire engineering team must then pivot their focus exclusively to fixing bugs, optimizing infrastructure, and restoring systemic reliability.
Toil — The Silent Productivity Killer in Infrastructure
Toil is the administrative, repetitive tax that drains engineering time, kills team morale, and introduces massive risk into live environments. Toil is characterized by work that is highly manual, entirely automatable, tactically reactive, and completely lacking in long-term engineering value.
To systematically eliminate this productivity killer, teams must track their daily activities and calculate exactly how many hours are spent on repetitive maintenance tasks. Once a recurring source of toil is identified, engineers must treat it as a bug that requires an automated software solution to fix.
By dedicating a fixed percentage of engineering time to automating away these manual tasks, organizations ensure their operational teams stay lean, focused, and highly strategic.
Incident Management & Postmortems
When unexpected infrastructure failures occur, teams must follow a highly structured incident management process to restore service as quickly as possible. This process includes spinning up dedicated communication bridges, assigning clear operational roles, and isolating failing components to minimize user blast radius.
Once the service is fully restored, the team must conduct a formal, completely blameless postmortem to dissect exactly what happened. A blameless culture assumes that engineers are always acting with good intentions based on the information they had at the time, and that failures are caused by broken systemic processes, not bad human actors.
The resulting postmortem document details the root cause of the incident, maps out the timeline of events, and creates a set of concrete, trackable engineering tasks to ensure the exact same failure can never happen again.
Capacity Planning
Capacity planning is the data-driven practice of forecasting future infrastructure needs to ensure systems stay online during massive consumer usage spikes. This discipline requires continuously analyzing historical telemetry trends, processing marketing event schedules, and calculating organic growth metrics.
Teams use this data to build predictive models that show exactly when existing compute pools, storage arrays, or network pipes will run out of headroom. Proper planning ensures that organizations can purchase infrastructure or adjust cloud limits long before resource exhaustion causes a massive outage.
In modern cloud environments, capacity planning also focuses deeply on architectural efficiency, ensuring teams scale down unneeded resources to eliminate massive financial waste.
The Four Golden Signals of Pipeline Performance
To maintain complete visibility into the health of a distributed pipeline, operations engineers focus intensely on tracking the four golden signals of system performance. Monitoring these four critical metrics allows teams to quickly diagnose the vast majority of user-facing issues.
- Latency: The precise time it takes for a system to process a specific request and return a response to the user. Teams track latency split between successful requests and failed requests to catch hidden performance anomalies.
- Traffic: A direct measure of the overall demand being placed on the system at any given moment. This is typically calculated in metrics like HTTP requests per second, database transactions per minute, or network data packets transferred.
- Errors: The overall rate of requests that are failing to process successfully. This metric includes explicit errors like internal server codes, implicit errors like missing content, and policy-driven timeouts.
- Saturation: A measure of how close a system resource is to reaching its absolute maximum capacity limit. This tracks highly constrained resources like CPU usage, memory allocation, or disk input-output queues.
Platform Implementation vs. Culture — What’s the Real Difference?
The Philosophy Difference
Many organizations mistake the implementation of modern operational software tools for the actual cultural adoption of an engineering philosophy. High-level culture focuses heavily on human behavior, cross-team collaboration, shared accountability, and a willingness to accept calculated risks.
In contrast, technical implementation deals with the concrete configuration of software tools, deployment code pipelines, and real-time dashboard visualizations. Buying a high-end enterprise observability platform does absolutely nothing to fix an internal culture where developers are punished for production mistakes.
True operational excellence occurs only when advanced technical platforms are used to support and reinforce a transparent, blameless cultural philosophy across the entire business.
Roles & Responsibilities Compared
While cultural frameworks and technical implementations work together, the day-to-day duties of specialists within these spheres differ significantly.
- Cultural Champions: Focus on breaking down organizational communication silos, teaching blameless postmortem practices, and aligning product managers on realistic reliability goals.
- Technical Implementation Specialists: Focus on writing configuration files, maintaining core infrastructure code, building automated monitoring pipelines, and building self-healing scripts.
- Operations Coordinators: Bridge both worlds by maintaining live systems, writing code to automate away repetitive tasks, and running incident response teams.
- Release Engineers: Focus entirely on optimizing the deployment pipeline, ensuring code moves safely from testing environments to live servers without causing downtime.
Can You Have Both Disciplines?
High-performance tech organizations do not choose between strong culture and advanced technical platforms; they integrate both into a single cohesive strategy. A healthy culture provides the psychological safety and clear communication paths necessary to navigate complex infrastructure failures without panic.
At the same time, an advanced technical platform gives engineers the exact data and automation tools they need to act on those cultural principles effectively.
When both elements are present, teams can move incredibly fast, knowing their tools will catch errors and their culture will treat those errors as valuable learning opportunities. This integration transforms operational infrastructure from an unstable bottleneck into a predictable engine for rapid business growth.
Which One Should Your Team Adopt?
Choosing where to focus your engineering resources depends entirely on your current organizational size and overall technical maturity.
- Early-Stage Startups: Should prioritize building a strong, flexible culture of shared operational responsibility before spending weeks configuring complex enterprise tooling.
- Mid-Sized Growing Businesses: Should focus on standardizing their deployment pipelines and setting up basic, clean observability platforms to handle growing customer traffic.
- Large-Scale Global Enterprises: Must invest heavily in both areas, establishing dedicated infrastructure platforms while continuously reinforcing a blameless engineering culture across hundreds of teams.
- Highly Regulated Corporations: Need to implement strict automated compliance and release controls within their technical platforms to meet safety standards without sacrificing velocity.
Real-World Use Cases of Modern Operations
How Tech Leaders Use Operational Metrics
The world’s most successful software companies manage their global infrastructure by turning every aspect of system performance into actionable, clean telemetry data. These organizations collect trillions of real-time operational metrics every single day, feeding them directly into centralized analytics dashboards.
By tracking these signals continuously, engineering leadership can spot macro-level efficiency trends, trace cross-service dependencies, and calculate the exact cost of running individual features. This deep data tracking allows executives to make smart infrastructure investment decisions based on real-world capacity usage rather than gut feelings.
Furthermore, these metrics are tied directly to automated alerting systems that immediately flag unusual anomalies, allowing engineers to fix problems long before they degrade the end-user experience.
Chaos Engineering Approaches to Resilient Systems
Waiting for a massive, unpredictable network failure to hit your production system during a major shopping holiday is a recipe for business disaster. To avoid this, advanced engineering teams practice chaos engineering—the disciplined practice of intentionally injecting controlled failures into live environments.
Automated tools are deployed to randomly shut down critical servers, drop network connectivity between data centers, or artificially inject high latency into core microservices. By breaking things on purpose during normal business hours, engineers can verify whether their self-healing systems and failover automation work perfectly.
This practice uncovers hidden architectural flaws, validates monitoring alerts, and ensures that the engineering team stays sharp and practiced at handling real-time system degradation safely.
Handling Reliability at Massive Scale
When an infrastructure platform scales to support tens of millions of concurrent users around the world, traditional single-datacenter management techniques break down completely. Global tech leaders handle this massive scale by building highly distributed, multi-region architectures that operate with zero single points of failure.
Applications are broken down into independent microservices that communicate using asynchronous messaging queues, ensuring that a failure in one service cannot cause a domino effect across the whole platform.
Traffic is continuously routed across global cloud regions using smart, geo-located load balancers that automatically bypass any data center experiencing hardware or network issues. This decentralized approach ensures that even during massive traffic spikes, the overall platform remains completely stable and available.
High-Availability in Fintech Operations
In the world of financial technology and digital payment processing, infrastructure downtime is measured not just in lost minutes, but in millions of dollars of lost transaction revenue. Fintech platforms require strict zero-tolerance architectures for both data loss and service interruption.
To achieve this, operations teams implement multi-region active-active database replication, where every financial transaction is processed and verified across multiple separate geographic zones simultaneously.
Every single infrastructure component, from network switches to security firewalls, is deployed with redundant failovers that kick in instantly without dropping active user sessions. Strict compliance checks and automated security scanning are built directly into the delivery pipeline, ensuring that every code release meets rigorous regulatory standards without slowing down deployment speed.
Scaled-Down but Essential Systems for Startups
You do not need a multi-million dollar infrastructure budget or a massive team of engineers to take advantage of modern operational principles. Early-stage startups apply these core strategies efficiently by utilizing managed cloud services and serverless architectures that handle underlying infrastructure maintenance automatically.
By adopting simple infrastructure-as-code scripts from day one, small teams can provision identical development, testing, and production environments in minutes.
Startups focus their limited engineering hours on setting up basic, high-impact observability dashboards and defining a few critical Service Level Objectives built directly around user onboarding. This lightweight, disciplined approach keeps operational overhead low, prevents technical debt from piling up, and ensures the startup’s platform is built to scale smoothly as customer demand grows.
Common Mistakes in Operations Engineering
Mistake 1 — Confusing System Management with Just Being On-Call
One of the most damaging mistakes an organization can make is treating their systems engineering team as a glorified, 24/7 manual help desk. When engineers spend their entire shifts frantically reacting to broken alerts, restarting servers, and patching live bugs, they have zero time left to do actual engineering work.
This reactive approach traps the team in a never-ending cycle of crisis management, while underlying structural infrastructure flaws go completely unaddressed.
Modern operations management is about proactive engineering—building smart software tools, automating recovery workflows, and designing resilient system architectures that eliminate the need for human intervention during an incident.
Mistake 2 — Setting Unrealistic SLOs
It is incredibly common for business executives or over-eager engineering leads to demand perfect one hundred percent uptime for their applications. However, setting an unrealistic Service Level Objective creates an incredibly hostile, slow-moving engineering environment.
Achieving ultra-high reliability targets requires massive financial investments, extreme architectural over-engineering, and intensive manual testing phases that grind feature delivery to an absolute halt.
Furthermore, demanding perfect uptime burns out your engineering talent, as teams live in constant fear of violating unachievable metrics. Objectives must always be balanced realistically against actual user expectations and broader business velocity requirements.
Mistake 3 — Ignoring Toil Until It’s Too Late
When teams are growing fast, it is incredibly easy to ignore small, repetitive manual tasks like running a quick manual database migration or manually resetting a stuck configuration file. However, this manual toil scales linearly alongside your system’s growth, quickly turning into a massive mountain of operational debt that consumes all engineering velocity.
Before you realize it, your highly skilled engineers are spending eighty percent of their week performing mind-numbing administrative maintenance rather than building scalability features.
Organizations must aggressively track, limit, and systematically script away these manual workflows before they completely crush engineering productivity and stall company innovation.
Mistake 4 — Skipping Blameless Postmortems
When a major production outage occurs and costs a business significant revenue, there is a natural corporate reflex to find someone to blame and punish. However, running a finger-pointing culture causes engineers to hide mistakes, cover up technical debt, and refuse to work on high-risk, high-reward infrastructure updates.
Skipping formal postmortems or turning them into blame-filled lectures ensures that your organization never learns why the failure actually happened.
Outages are always the result of complex, underlying systemic flaws within your processes or tools; identifying those flaws requires absolute transparency, psychological safety, and a shared commitment to continuous structural learning.
Mistake 5 — Monitoring Without Actionable Alerts
Building massive, complex dashboards that track thousands of random infrastructure metrics sounds impressive, but it often leads to extreme alert fatigue. When engineers are constantly bombarded with non-actionable notifications, noisy text messages, and low-priority warning emails, they quickly learn to ignore alerts altogether.
Eventually, a truly catastrophic infrastructure failure occurs, and the critical notification is missed because it was buried under a mountain of low-priority background noise.
Every single alert that routes directly to an on-call engineer must be high-priority, strictly actionable, and tied directly to a real-world degradation of user experience. If an alert does not require immediate human intervention to fix, it should be logged silently or handled by an automated script.
Mistake 6 — Not Involving Operational Engineers in the Design Phase
Far too many organizations allow software developers to design large-scale application architectures completely in isolation, only looping in operations teams right before the final production release. This complete lack of collaboration results in software that is incredibly difficult to deploy, impossible to monitor effectively, and highly fragile under heavy load.
System architectural design requires deep operational input from day one to ensure that scalability, observability, and failover capabilities are woven directly into the code fabric.
Involving systems specialists early saves massive amounts of engineering hours, prevents costly late-stage architectural rewrites, and guarantees a smooth transition from testing environments to live global production.
Essential Infrastructure Tools & Technologies
Monitoring & Observability
To maintain deep visibility into complex cloud-native architectures, modern operations teams rely on a powerful stack of monitoring and telemetry platforms. Prometheus has become the industry standard for open-source metric collection and time-series data aggregation, allowing teams to query performance metrics with immense precision.
Grafana integrates seamlessly on top of these data sources, turning raw telemetry into beautiful, easily digestible, real-time visualization dashboards.
For full-stack enterprise observability, platforms like Datadog and New Relic provide deep application performance monitoring, distributed tracing, and automated log analysis across thousands of distributed microservices. These tools ensure engineers spot hidden infrastructure bottlenecks instantly before they impact users.
Incident Management
When an unexpected infrastructure failure occurs, teams use dedicated incident management platforms to coordinate their engineering response and streamline communications. PagerDuty acts as the primary routing engine for production alerts, utilizing smart scheduling to wake up the correct on-call specialist the moment a Service Level Objective is threatened.
This platform integrates deeply with tools like Slack and Microsoft Teams, allowing organizations to run ChatOps workflows where engineers can triage incidents directly from communication channels.
These incident management suites log every step of the response timeline automatically, providing critical data that teams use later during their blameless postmortem analysis.
CI/CD & Release Engineering
Automating the movement of code from developer repositories to live servers requires robust continuous integration and continuous deployment engines. Jenkins remains a widely used, highly customizable workhorse for building and testing software packages automatically.
In the cloud-native ecosystem, git-driven continuous delivery tools like Argo CD and Spinnaker have completely revolutionized how infrastructure is updated.
These platforms pull configuration code directly from Git version control repositories and apply it across massive container clusters automatically, ensuring production environments match the desired state perfectly. This automation eliminates human deployment errors and allows for safe, instantaneous rollbacks if an update fails.
Chaos Engineering
Intentionally breaking live enterprise infrastructure requires highly specialized, controlled safety tools designed to inject failures without causing unmanageable disasters. Chaos Monkey, originally pioneered by industry streaming leaders, remains a classic tool for randomly terminating production server instances to verify system self-healing capabilities.
For more advanced, highly targeted experimentation, platforms like Gremlin allow engineers to inject precise amounts of network latency, CPU saturation, or disk failure into specific microservices.
These chaos engineering platforms feature built-in automated kill switches that instantly stop all active failure experiments and restore normal infrastructure states if system degradation exceeds safe, pre-defined thresholds.
SLO Management
As organizations shift toward data-driven reliability management, tracking Service Level Objectives has evolved into its own dedicated software category. Nobl9 is a leading platform designed explicitly to aggregate performance data from multiple monitoring sources and calculate error budgets in real-time.
These specialized tools allow product managers and infrastructure engineers to collaborate on setting realistic reliability targets within a single dashboard interface.
SLO management software alerts teams when their error budget consumption rate spikes unexpectedly, providing the early warning signals needed to halt risky feature releases and protect the overall user experience.
How to Become an Operations Expert — Career Roadmap
Skills Every Specialist Must Have
Breaking into the world of high-scale systems management requires a deep, versatile blend of software engineering skills and system administration fundamentals. Every specialist must master the Linux command line, developing absolute comfort navigating directory structures, analyzing system logs, and managing running processes via the terminal.
Scripting proficiency in languages like Python or Go is non-negotiable, as you will use these languages daily to build automation tools and manage infrastructure code APIs.
Additionally, you must understand core networking protocols like TCP/IP, DNS routing, and HTTP headers inside and out. Finally, expertise in infrastructure-as-code platforms and basic cloud architecture concepts is absolutely critical for deploying and managing modern virtual environments.
The Professional Learning Path
The educational journey toward becoming a senior systems architect requires a disciplined, step-by-step progression through increasingly complex technical domains.
By methodically checking off each stage of this learning path, you build the deep, foundational engineering intuition required to debug massive, highly distributed global networks under pressure.
Certifications Worth Pursuing
While real-world hands-on engineering experience is always the ultimate credential, industry-recognized certifications can significantly accelerate your career path and validate your technical expertise. Earning advanced cloud credentials from major providers like Amazon Web Services or Google Cloud Platform proves you understand how to architect secure, highly available cloud systems.
In the container ecosystem, the Certified Kubernetes Administrator (CKA) and Certified Kubernetes Application Developer (CKAD) designations are highly respected, practical credentials that demonstrate deep container orchestration mastery.
Pursuing these structured certification paths helps bridge gaps in your technical knowledge and showcases your dedication to mastering modern infrastructure engineering to potential employers.
Educational Resources with waropsx.com
To truly accelerate your transformation from a traditional system administrator into a world-class operations specialist, you need access to deep, highly practical educational materials. Exploring the advanced training programs, comprehensive course deep-dives, and real-world architectural blueprints provided by waropsx.com is an exceptional way to sharpen your technical edge.
Their specialized content skips the generic marketing fluff and focuses intensely on the real-world engineering scenarios, automation scripting strategies, and live incident response skills that top-tier enterprise companies demand.
Leveraging these expert-led resources allows you to master complex infrastructure design patterns, learn how to manage error budgets effectively, and position yourself as an invaluable technical leader in the modern engineering marketplace.
The Future of Systems Management
AI and Automation in System Optimization
The next major evolutionary leap in infrastructure management is the rapid integration of machine intelligence and automated anomaly detection into the core operational pipeline. As distributed systems generate petabytes of real-time telemetry data, human engineers can no longer parse through logs fast enough to find subtle, hidden failure root causes.
AI-driven optimization engines are stepping into this gap, continuously scanning system signals to detect microscopic performance trends that indicate a looming hardware or software failure.
These intelligent systems can automatically adjust resource allocations, optimize database query paths, and even trigger automated code fixes to remediate issues entirely without human intervention. This shift allows infrastructure to adapt and optimize itself dynamically in real-time based on actual live user behavior.
Platform Engineering — The Evolution of Infrastructure
Infrastructure management is rapidly evolving beyond the practice of having a dedicated operations team manually manage cloud resources for individual development groups. The industry is shifting heavily toward platform engineering—the discipline of building internal self-service developer platforms that abstract away underlying infrastructure complexity completely.
Senior systems experts now focus on building these internal portals, allowing software developers to provision secure, compliant, and fully observable cloud environments with a single click.
This model removes organizational friction, eliminates ticket-based deployment queues, and ensures that company-wide security and reliability standards are automatically baked into every single microservice from the moment it is created.
Management in Cloud-Native & Kubernetes Environments
As global business enterprises migrate their core workloads into dynamic, highly ephemeral container environments, managing cluster orchestration has become a principal engineering challenge. Kubernetes has won the container race completely, but its massive surface area introduces significant architectural complexity and abstract failure modes.
Future operations management requires mastering deep container networking, service mesh technologies, and multi-cluster governance strategies that span across multiple cloud providers simultaneously.
Engineers must design automated systems that handle rapid container autoscaling, secure cross-cluster communication, and stateful database management across thousands of transient nodes, ensuring absolute data integrity and zero user-facing disruption.
Operational Skills That Will Matter Most
In the rapidly approaching future of enterprise tech, the most successful systems specialists will be those who combine deep technical engineering acumen with sharp financial and analytical skills. As cloud expenditures skyrocket across the corporate landscape, financial cost optimization—often called FinOps—has become a mission-critical operational priority.
Engineers must learn to design architectures that are not only highly reliable but also incredibly cost-efficient, dynamically scaling down resources to eliminate waste.
Additionally, deep data literacy and advanced telemetry analysis skills will matter immensely, as the ability to extract actionable business insights from massive pools of distributed system logs separates elite platform architects from traditional maintenance staff.
FAQ Section
- What is the typical career path for someone entering the systems operations field?
Most specialists begin their professional journeys as junior software developers or traditional systems administrators, focusing heavily on learning core operating system internals, basic scripting, and fundamental networking. Over time, they transition into dedicated systems infrastructure roles, where they take on complex automation scripting, cloud architecture provisioning, and advanced telemetry management duties. Senior professionals eventually advance into high-level platform architects or infrastructure engineering managers, where they design long-term architectural blueprints, establish company-wide reliability goals, and lead enterprise-wide digital transformation strategies.
- How does an operations specialist differ from a traditional systems administrator?
A traditional systems administrator focuses heavily on manually configuring servers, installing software updates by hand, and reacting to system failures after they occur, which scales linearly with infrastructure size. In stark contrast, a modern operations specialist treats infrastructure as a pure software engineering problem, writing code to automate provisioning, scaling, and self-healing workflows. Traditional administrators spend their days performing manual maintenance tasks, while modern operations engineers dedicate their time to building automated tools that eliminate repetitive work completely, allowing massive networks to scale efficiently without a corresponding increase in team size.
- What are the current salary trends for experienced infrastructure engineers?
Due to the massive, universal corporate demand for highly resilient cloud infrastructure, experienced systems management specialists command some of the highest compensation packages in the global technology industry. Entry-level engineers with solid automation and cloud fundamentals command highly competitive salaries, while mid-career specialists see substantial increases as they master container orchestration and deep observability platforms. Senior architects and principal infrastructure engineers who can design multi-region, self-healing enterprise environments frequently earn premium executive-level compensation, making this career path exceptionally lucrative and stable.
- Why is a blameless culture considered so critical for maintaining system reliability?
When an organization implements a culture focused on finger-pointing and punishment, engineers naturally become terrified of making mistakes, leading them to hide operational technical debt, cover up system failures, and avoid deploying innovative features. A blameless culture flips this dynamic completely by assuming that human errors are merely symptoms of deeper, broken systemic processes and inadequate tooling. This psychological safety allows teams to analyze production failures with absolute honesty, uncover true architectural root causes, and build robust automated safeguards that prevent the exact same incident from ever happening again.
- How much software programming knowledge do I actually need to excel in this role?
You do not need to be an expert in building complex front-end user interfaces, but you absolutely must possess solid, production-grade backend programming and scripting skills to excel. Specialists must be fully proficient in languages like Python, Go, or Ruby to write clean automation scripts, interact with complex cloud APIs, and build internal deployment tools. You must understand software design patterns, code version control via Git, and continuous integration pipelines inside and out, as your entire job revolves around writing software to manage, monitor, and scale physical infrastructure.
- What is alert fatigue and how can engineering teams actively prevent it?
Alert fatigue is a dangerous operational state that occurs when on-call engineers are continuously bombarded by a non-stop stream of low-priority, noisy, or non-actionable monitoring notifications throughout their shifts. Over time, the human brain naturally tunes out these alerts, meaning that when a truly catastrophic system failure occurs, the critical notification is completely missed. Teams prevent this disaster by strictly auditing their monitoring systems, ensuring that only critical, user-impacting violations of Service Level Objectives route directly to a human being, while all minor warnings are handled by automated scripts.
Conclusion
Maintaining the long-term health, performance, and resilience of massive global infrastructure requires a complete departure from the reactive, manual operational models of the past. True systemic stability is achieved only when organizations commit to treating infrastructure as a core engineering discipline, utilizing data-driven Service Level Objectives, and aggressively automating away manual technical debt. By cultivating a transparent, blameless engineering culture and implementing advanced observability frameworks, businesses can confidently accelerate feature delivery without sacrificing customer experience.
As technologies continue to shift toward highly dynamic cloud-native platforms, mastering these core architectural principles will separate market leaders from fragile organizations. To stay ahead of these complex trends and build the elite infrastructure skills your business demands, continue your learning journey with the professional blueprints and educational resources found at waropsx.com.