Introduction
The architecture supporting enterprise IT is experiencing a massive structural shift. As organizations replace old, single-piece software setups with highly split, cloud-native systems, managing day-to-day operations has become incredibly complicated. Modern microservices, ephemeral containers, and multi-cloud setups move fast and generate mountains of operational data every single second. Traditional system monitoring—which depends entirely on engineers setting up rigid, static thresholds—simply cannot keep up with this pace, leaving companies exposed to hidden infrastructure failures.For technology professionals who want to lead this transition, mastering these data-driven patterns is a major career advantage. AIOpsSchool serves as a premier, dedicated learning environment built specifically to bridge the gap between traditional software management and modern, intelligent orchestration. By offering highly structured learning tracks, hands-on infrastructure sandboxes, and targeted credential preparation, the platform helps engineers, administrators, and tech architects confidently build and run modern, self-healing platforms.
Featured Snippets
What is AIOps?
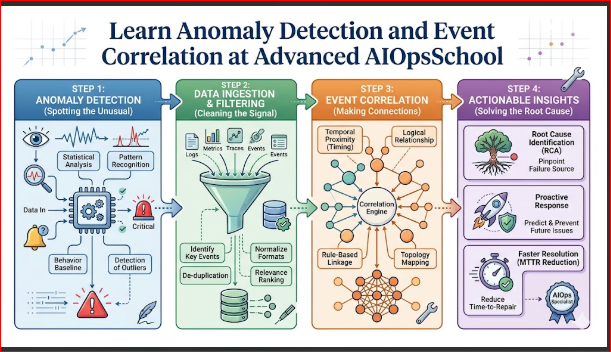
AIOps stands for Artificial Intelligence for IT Operations. It is the practice of combining big data frameworks and machine learning algorithms to automate and streamline infrastructure management. By parsing metrics, logs, and traces at scale, it automates event correlation, surfaces hidden anomalies, and identifies cross-domain root causes without relying on static human rules.
What is AIOps Training?
AIOps training is a practical educational roadmap designed to teach technology professionals how to apply data science, automated workflows, and observability practices to live production systems. It transforms traditional infrastructure administrators into specialized engineers capable of building intelligent, automated platform ecosystems.
What is AIOps Certification?
An AIOps certification is an industry-recognized professional credential that validates an engineer’s practical ability to deploy algorithmic monitoring setups, map complex application topologies, structure automated data pipelines, and design secure self-healing workflows.
Why is AIOps important?
AIOps is critical because modern cloud infrastructures produce far too much complex, high-velocity telemetry data for human operators to analyze manually. It cuts out up to 90% of alert noise, prevents expensive system downtime through predictive insights, and significantly reduces Mean Time to Resolution (MTTR).
What are AIOps tools?
AIOps tools are advanced enterprise software platforms that ingest wide-reaching operational data to analyze it using machine learning models. These tools break down traditional infrastructure data silos to provide unified, cross-stack operational intelligence and visibility.
What is anomaly detection in AIOps?
Anomaly detection in AIOps is the process of using automated machine learning algorithms to map out an evolving behavioral baseline of normal infrastructure performance, allowing the system to instantly flag statistical deviations in real time without manual threshold configuration.
What is root cause analysis in AIOps?
Root cause analysis (RCA) in AIOps is the automated process of tracking infrastructure topology dependencies, system logs, and concurrent event timings to instantly point out the exact underlying fault that triggered an operational failure.
What Is AIOps?
To successfully pivot toward an automated operational model, it helps to look at AIOps as a profound evolution in how enterprise systems track and communicate their internal health. Coined by industry analysts to describe the intersection of big data, analytics, and software engineering, AIOps represents an intelligent upgrade to traditional system oversight.
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ Ingest Telemetry │ ──> │ Algorithmic Layer│ ──> │ Executable Info │
│ (Metrics/Logs) │ │ (ML & Analytics) │ │ (& Smart Action) │
└──────────────────┘ └──────────────────┘ └──────────────────┘
The Changing Landscape of System Verification
- Manual Log Checking: In the early days of IT, system administrators had to physically log into servers to read text files or check basic hardware availability graphs.
- Fixed Boundary Rules: As virtual machines became popular, monitoring systems introduced fixed limits (e.g., “Alert if memory use passes 85%”). This approach causes issues because it fails to understand seasonal traffic shifts, leading to constant false alarms.
- Algorithmic Observability: Modern intelligent management uses machine learning models to track performance trends over long windows. The system learns what normal behavior looks like based on real usage patterns, filtering out standard seasonal variations while immediately highlighting genuine, multi-system anomalies.
By breaking down the data walls between isolated monitoring applications, an enterprise-wide AIOps setup builds a singular, unified data pool. This holistic perspective turns messy, raw operational data into clear, predictive insights.
What Is AIOpsSchool?
AIOpsSchool is a specialized online learning ecosystem built specifically to solve the skills shortage within modern infrastructure engineering. While standard data science programs focus heavily on general statistics or consumer analytics, AIOpsSchool dedicates its entire curriculum to the unique requirements of production IT environments, deep system automation, and modern observability patterns.
The platform is built to support technology professionals at all stages of their career progression, turning abstract data concepts into clear, step-by-step implementation practices. Rather than spending weeks on theoretical formulas, students spend their time learning how to construct high-fidelity data pipelines, clean unstructured system logs, feed streaming time-series data into analytical engines, and safely connect those insights to production automation tools.
Through its modular tutorials, structured paths, and formal certification preparatory resources, AIOpsSchool gives you the practical blueprints needed to drive real operational transformation.
Why AIOps Is Important in Modern IT Operations
The rapid shift toward cloud-based software deployment has made traditional “wait-until-it-breaks” operations models a massive business liability. Enterprises globally are migrating to intelligent, data-driven platforms due to several severe infrastructure challenges:
- Ephemerality and Microservices: Modern business software is built from thousands of small, decoupled services running inside container clusters that scale up or down automatically. Because a single container might only exist for a few minutes, traditional static tools can miss its behavior completely, making manual debugging almost impossible.
- The High-Velocity Telemetry Explosion: Distributed systems generate terabytes of structural data every day in the form of metrics, logs, and traces. Human operations teams cannot physically parse, filter, or find meaningful correlations within datasets of this scale without algorithmic filters running in the background.
- Eliminating Internal Silos: When a core infrastructure failure happens, downstream application layers fail sequentially. This causes multiple isolated monitoring tools to send out separate, high-priority notifications simultaneously. An AIOps strategy uses automated event correlation to group these separate symptoms into a single, cohesive incident ticket, directing engineers straight to the root source of the problem.
- Protecting User Experience and Revenue: In modern digital markets, even a few minutes of application latency or downtime can directly damage consumer trust and cost companies millions in lost transactions. Moving to a predictive operational stance allows teams to catch and resolve performance risks long before they affect user-facing interfaces.
Who Should Learn AIOps?
The modern skills taught throughout advanced operational programs provide significant professional leverage across a wide variety of engineering domains:
DevOps Engineers
DevOps specialists use AIOps concepts to build highly intelligent continuous deployment pipelines. By injecting automated anomaly detection into software rollouts, they can automatically trigger a safe rollback the moment live telemetry indicates abnormal post-release system behavior.
SRE Engineers (Site Reliability Engineering)
For reliability teams, maintaining high availability while managing extreme architectural complexity is the ultimate metric. AIOps for SRE offers the design patterns needed to minimize overall notification volumes, protect team error budgets, and build resilient self-healing architectures that lower MTTR.
Cloud and Platform Specialists
Engineers managing sprawling AWS, Azure, or Kubernetes clusters rely on predictive analytics to accurately forecast resource scaling needs, uncover hidden cloud cost inefficiencies, and safely coordinate automated infrastructure adjustments without risking application performance.
Systems and Monitoring Administrators
Traditional infrastructure professionals can easily elevate their daily skillsets away from manual alert clearing toward high-value platform orchestration. Mastering AIOps workflows empowers these specialists to design and supervise the very automated engines that handle initial tier-1 incident triaging.
IT Leadership and Technology Directors
CTOs, infrastructure architects, and enterprise managers need a strong conceptual understanding of intelligent use cases to make smart tooling investments, structure high-performing operations teams, and successfully guide long-term digital transformations.
Key Features of AIOps Training Programs
AIOpsSchool formats its entire educational framework around real-world capability and hands-on competence:
- Progressive Learning Tracks: Courses are arranged sequentially, ensuring students clear core data collection and telemetry fundamentals before advancing to advanced predictive forecasting and model configuration.
- Hands-On Sandbox Laboratories: Lectures are paired with safe, isolated cloud labs where students interact with real infrastructure environments, observe live simulated system failures, and configure analytics tools to isolate faults.
- Enterprise Outage Blueprints: Training scenarios are drawn directly from real corporate case studies, giving students practical experience troubleshooting high-pressure, large-scale distributed infrastructure crises.
- Practical Tool Orchestration: The curriculum showcases exactly how industry-standard data collectors, open-source visualization systems, and enterprise automation engines mesh seamlessly with machine learning components.
- Automated Topology Mapping: Students gain deep familiarity with mapping complex application dependencies, learning how mathematical correlation algorithms leverage structural maps to locate hidden operational errors.
AIOps Certification: Why It Matters
As corporations invest heavily into building out modern, intelligent platform visibility, they require clear evidence that their engineering teams know how to configure and run these advanced systems. Obtaining an AIOps Foundation Certification provides verified proof of your operational and architectural expertise.
From a career advancement perspective, holding a specialized, forward-looking certification sets a professional apart in a competitive hiring environment. It proves to technical management that you possess a rare mix of core infrastructure knowledge and modern data analytics capabilities. For organizations, utilizing certified talent significantly mitigates implementation risks, ensures faster ROI on new monitoring platforms, and ensures compliance with modern service reliability standards.
AIOps Course Curriculum Components
A comprehensive training program must balance structural system engineering with applied data analytics. The AIOpsSchool curriculum breaks down into these fundamental components:
1. High-Fidelity Data Ingestion and Telemetry Strategy
Before you can run advanced machine learning models, you must build clean, standardized data streams. This module focuses on capturing and formatting the three essential elements of system observability: metrics (numeric infrastructure values), logs (textual event records), and traces (the structural journey of an execution request through code blocks).
2. Practical Data Science for Systems Engineering
Students dive into the specific analytical models designed for telemetry processing. This includes using clustering algorithms to group log entries, regression analysis for long-term capacity forecasting, and signal processing to separate normal system behavior from severe infrastructure alerts.
3. Smart Event Consolidation and Alert Refinement
This section details how to eliminate background noise through intelligent deduplication and topology analytics. Engineers learn how to craft rules that process thousands of chaotic point-alerts across a server cluster and condense them into a single, comprehensive operational incident.
4. Continuous Anomaly Recognition and Evolving Baselines
Move completely away from brittle static rules. This module teaches professionals how to implement dynamic behavioral baselining, configuring algorithms that understand seasonal spikes (such as high midday transactional traffic) while catching subtle, abnormal shifts that require immediate investigation.
5. Automated Remediation and Closed-Loop Orchestration
The primary objective of advanced operational engineering is reducing human triage time. This block focuses on linking machine learning diagnostics with script-execution runbooks, enabling the environment to automatically deploy targeted fixes safely and securely without human intervention.
AIOps Tools and Technologies
An effective platform architect must understand how distinct software types connect to form a cohesive, intelligent operations framework. The table below outlines how these components interact:
| Tool Category | Purpose | Benefits | Typical Use Cases |
| Observability Platforms | Aggregate and correlate metrics, logs, and traces globally across cloud environments. | Eliminates data silos, providing an unbroken view across different software components. | Mapping complex request routing across hundreds of microservice nodes. |
| Log Analytics Systems | Collect, index, and query vast streams of textual system log data. | Delivers rapid text pattern discovery and fast historical search execution. | Inspecting specific database error codes during an active performance regression. |
| Event Orchestration Engines | Centralize, filter, and group massive volumes of system-wide notifications. | Minimizes notification fatigue by condensing matching alerts into clean incidents. | Grouping 500 separate container-drop notifications into 1 actionable alert. |
| Automation & Playbook Tooling | Run targeted scripts, configure resources, and execute system rollbacks. | Minimizes manual turnaround times while executing highly consistent system fixes. | Automatically provisioning extra storage or executing a safe application restart. |
| AI/ML Core Components | Apply mathematical modeling to continuous, incoming streams of time-series data. | Offers automated behavioral tracking and intelligent capacity forecasting. | Discovering a slow application memory leak over a rolling multi-week period. |
AIOps Use Cases in Real Enterprises
Applying the methodologies taught in an advanced AIOps course directly addresses the most pressing operational challenges found in corporate environments:
- Intelligent Alert Reduction: A major enterprise application was generating more than 40,000 automated system alerts per week, leading to critical failure indicators being missed by on-call engineers. By rolling out an event correlation framework, the team automatically grouped duplicate reports and filtered out normal background noise, bringing their weekly ticket count down to less than 300 highly focused, actionable incidents.
- Accelerated Diagnostic Discovery: When a multi-tier e-commerce platform suffered sudden payment processing slowdowns, engineering departments typically spent hours in virtual war rooms trying to isolate the failure. An analytical AIOps engine can parse live system topology maps, correlate a database connection exhaustion with the checkout lag, and instantly flag the exact misconfigured application container.
- Algorithmic Resource Forecasting: Using advanced regression models, a corporate cloud optimization team can track long-term infrastructure consumption patterns. Instead of waiting for a storage cluster to hit full capacity and crash dependent systems, the engine calculates the exact date resources will be depleted and automatically creates an optimization ticket to safely scale out storage.
- Closed-Loop Infrastructure Recovery: In many enterprise setups, a legacy backend system might experience occasional memory leaks that cause it to freeze. An AIOps framework monitors this pattern, confirms it matches a known behavioral signature, isolates the single affected container, and triggers a secure restart script—resolving the user-facing issue automatically within moments without waking up an engineer.
AIOps for SRE Teams
Site Reliability Engineers use quantifiable telemetry data to defend platform reliability, manage error budgets, and ensure highly available infrastructure.
┌─────────────────────┐ ┌─────────────────────┐ ┌─────────────────────┐
│ High-Volume Metrics │ ──> │ Algorithmic Dynamic │ ──> │ Context-Rich Alerts │
│ & Telemetry Streams │ │ Anomaly Evaluation │ │ to SRE Engineers │
└─────────────────────┘ └─────────────────────┘ └─────────────────────┘
Intelligent AIOps platforms align perfectly with SRE objectives by transforming traditional alert logic. Instead of waking up engineers with volatile, short-lived metrics spikes that resolve on their own, the analytical engine presents context-rich incident packages that contain relevant logs, recent system changes, and matching remediation workflows directly inside the ticket.
By delegating basic triaging and alert sorting to an automated platform, SRE teams free up their engineering time to focus on architectural improvements, deep post-mortem analysis, and creating scalable automation code.
AIOps vs DevOps
While both methodologies share a common goal of enhancing software delivery speed and system agility, they target entirely different parts of the application lifecycle:
| Area | DevOps | AIOps | Business Impact |
| Primary Focus | Restructuring communication and workflows between development and operational teams. | Utilizing big data structures and machine learning to analyze active infrastructure data. | DevOps speeds up code iteration cycles; AIOps ensures those deployments remain reliable. |
| Operational Strategy | Building automated continuous integration and continuous deployment pipelines. | Executing continuous telemetry analytics, event clustering, and trend forecasting. | DevOps minimizes code delivery friction; AIOps lowers MTTR when production issues emerge. |
| Core Success Metrics | Deployment frequency, delivery lead time, and overall change failure rates. | Mean Time to Detect (MTTD), Mean Time to Resolution (MTTR), and overall system availability. | Combined, they create a highly resilient software delivery pipeline built for web-scale demand. |
AIOps vs MLOps
It is easy to conflate these terms because they both involve data science patterns, but their targets and implementation goals are completely distinct:
| Area | AIOps | MLOps |
| Core Objective | Utilizing machine learning models to watch, understand, and optimize traditional IT infrastructure and multi-tier apps. | Standardizing the testing, delivery, version tracking, and ongoing health monitoring of machine learning models themselves. |
| Primary Practitioner | Site Reliability Engineers, DevOps Engineers, Cloud Platform Administrators, and Enterprise Monitoring Specialists. | Data Scientists, Machine Learning Engineers, AI Research Software Engineers, and MLOps Engineers. |
| Data Types Managed | Continuous infrastructure logs, time-series metrics, distributed transaction traces, and incident history data. | Large training datasets, validation features, hyperparameter weights, and model tracking metrics. |
How Anomaly Detection Works in AIOps
Understanding how algorithmic tracking functions allows platform engineers to design more efficient alerts. The anomaly detection sequence maps out into a continuous loop:
┌─────────────────────────┐ ┌─────────────────────────┐ ┌─────────────────────────┐
│ Ingest Time-Series Data │ ──> │ Calculate Live Baseline │ ──> │ Compare and Highlight │
│ from Across Stack │ │ using Machine Learning │ │ Statistical Deviations │
└─────────────────────────┘ └─────────────────────────┘ └─────────────────────────┘
- Continuous Telemetry Processing: The AIOps platform ingests continuous time-series metrics across every layer of the infrastructure stack.
- Building Evolving Baselines: Rather than relying on rigid, human-configured lines, the system uses machine learning models to analyze historical patterns, learning how performance shifts safely across different days or business cycles.
- Real-Time Metric Evaluation: As incoming production data arrives, the engine continually benchmarks live performance metrics against the upper and lower limits of the calculated dynamic baseline.
- Contextual Notification Delivery: If a metric breaches the dynamic boundaries, the platform evaluates neighboring system data to confirm the deviation isn’t just an isolated, harmless data spike. If the pattern is genuinely abnormal, it alerts the on-call team with full diagnostic details.
Root Cause Analysis in AIOps
Traditional root cause investigation is often slow and highly fragmented. When a complex application fails, engineers from different departments (such as database, network, and frontend teams) are forced to assemble in virtual war rooms, manually combing through individual dashboards to prove their respective infrastructure layer isn’t the source of the issue.
Automated root cause analysis eliminates this friction by leveraging live architectural data. The AIOps platform continuously evaluates live system topology maps, keeping track of how application components rely on underlying microservices, databases, and network pathways.
When an unexpected failure surfaces, the engine matches the timing of the initial anomaly with concurrent software updates, server modifications, or network changes. This allows it to trace the path of performance degradation directly back through the dependency graph, presenting engineers with the exact point of origin and bypassing hours of manual troubleshooting.
Observability and AIOps
Observability and AIOps work together as deeply complementary engineering disciplines. Modern observability centers on exposing the detailed internal health of an application by collecting high-fidelity data across three distinct telemetry vectors:
┌─────────────────┐
│ System Metrics │
│ (Numerical Data)│
└────────┬────────┘
│
┌─────────────────┐ ▼ ┌─────────────────┐
│ Historical Logs ├───────────────┤ Execution Traces│
│ (Textual Context)│ │ (End-to-End Map)│
└─────────────────┘ └─────────────────┘
- System Metrics: Highlight what symptoms are manifesting (such as elevated error rates or dropping memory space).
- Historical Logs: Deliver the deep structural why via descriptive textual statements generated by the software code.
- Execution Traces: Map out exactly where latency or network bottlenecks occur as an active request traverses separate microservices.
Observability provides the raw visibility across your environments, but raw telemetry data alone does not solve complex production incidents. AIOps functions as the intelligent processing layer that acts on top of this visibility. While observability captures the foundational telemetry data, AIOps delivers the automated insight needed to evaluate that information at scale, isolate hidden patterns, and trigger intelligent corrections.
Real-World Learning Scenarios
To see how advanced operations concepts reshape daily infrastructure management, consider these real-world career profiles:
Profile A: The Deployment Engineer
A DevOps specialist noticed that production code updates occasionally introduced minor database latency spikes that evaded standard automated testing tools. After completing their AIOps training path, they integrated an anomaly-detection pipeline directly into their deployment architecture. Now, the platform monitors database performance for fifteen minutes post-release; if any deviation from the historical baseline emerges, it executes an automated rollback before end users experience any issues.
Profile B: The SRE Team Lead
An SRE manager is tasked with maintaining uptime for a highly active multi-tenant cloud service. The team’s biggest challenge was excessive notification noise during predictable high-traffic sales periods. Utilizing event correlation principles learned at AIOpsSchool, they built an analytics layer that groups hundreds of scattered container alerts into singular, highly focused incident reports, dropping overall notification volumes by 85% and protecting team focus.
Profile C: The Cloud Migration Project
An IT operations team is migrating a core business system from on-premises hardware into a hybrid cloud configuration. Lacking unified visibility across both environments, they experienced high MTTR during network handoffs. By applying topology mapping and automated root cause analysis patterns, they created an operational baseline that spans both environments, allowing them to isolate connection drops instantly.
Career Opportunities After Learning AIOps
The enterprise market demand for platform professionals who can run AI-driven IT operations continues to expand rapidly. Completing your AIOps training opens up high-impact roles across modern tech organizations:
- AIOps Solutions Architect: Focuses on designing, building, and maintaining the core telemetry channels, streaming data pipelines, and analytical machine learning models that power the enterprise monitoring stack.
- Site Reliability Engineer (SRE): Leverages automated alerting and robust infrastructure execution frameworks to protect application availability and preserve team error budgets.
- Cloud Platform Architect: Focuses on designing scalable multi-cloud monitoring strategies, automated resource-capacity forecasting, and intelligent scaling logic.
- Systems Automation Engineer: Specializes in building secure self-healing frameworks, playbook webhooks, and execution logic that turn machine learning alerts into automated infrastructure corrections.
- DevOps Telemetry Specialist: Integrates telemetry feedback loops straight into continuous software packaging lines to optimize overall production application stability.
Common Mistakes Beginners Make When Learning AIOps
Transitioning into intelligent platform operations requires avoiding several common conceptual traps:
- Viewing it Only as a Software Install: Many beginners assume that purchasing an AIOps tool will instantly solve their infrastructure issues. Tools are ineffective without clear data hygiene, custom behavioral baselines, and a thorough understanding of your core operational workflows.
- Skipping Monitoring Fundamentals: You cannot design or configure advanced anomaly detection models if you don’t understand how foundational metrics collection, log storage strategies, and networking work. Always build a solid understanding of core monitoring first.
- Ignoring Unified Observability: Running machine learning algorithms against fragmented, low-quality data silos results in inaccurate alerts and false positives. Mastering the fundamentals of unified metrics, logs, and traces is a strict prerequisite.
- Overcomplicating Automation Early: Beginners often try to deploy fully automated self-healing workflows on day one. Start small: focus on automating initial data collection and incident triaging before allowing scripts to automatically alter production environment states.
Tips for Successfully Learning AIOps
To optimize your studies and master these complex operational practices efficiently, implement this practical approach:
- Follow a Sequenced Educational Pathway: Avoid jumping straight into complex machine learning math. Use a dedicated learning platform like AIOpsSchool to systematically build your skills from basic data collection up to advanced automated workflows.
- Prioritize Sandbox Laboratory Practice: Theoretical concepts fade quickly without direct application. Always reinforce classroom lectures by logging into sandbox platforms, manipulating messy log files, and configuring actual anomaly detection models.
- Master Core Principles Over Specific Tools: Avoid trying to learn a dozen different enterprise monitoring suites simultaneously. Focus on mastering the underlying architectural concepts (such as event correlation and dynamic baselining) inside one system; those core skills will easily transfer to any other tool suite.
- Analyze Public Post-Mortem Documentation: Study public outage reports from major technology firms. Trace how automated root cause analysis or faster event grouping could have prevented or mitigated those specific high-profile incidents.
AIOps Training Features Comparison Table
When evaluating how to invest your professional development time, choose an educational approach that delivers balanced practical skills:
| Core Training Feature | Practical Implementation Goal | Direct Learning Benefit | Long-Term Career Value |
| Interactive Sandbox Laboratories | Provides safe, isolated cloud platforms to practice code configurations. | Converts abstract data science theory into repeatable engineering skills. | Validates to technical recruiters that you can configure active software systems. |
| Structured Learning Roadmaps | Guides students step-by-step from data collection to advanced analytics. | Eliminates study fatigue by ensuring core technical prerequisites are cleared first. | Accelerates your learning timeline from an infrastructure beginner to a specialist. |
| Credential Examination Preparation | Equips engineers with the knowledge required to clear formal certifications. | Distills extensive course material down into high-priority architectural concepts. | Delivers an independent validation of your skills that stands out on engineering CVs. |
| Enterprise Use Case Focus | Explores documented real-world production failures and system setups. | Teaches you how to navigate high-pressure production system crises. | Prepares you to immediately tackle complex, large-scale infrastructure challenges. |
Future of AIOps
The trajectory of AI-driven infrastructure management is moving rapidly toward fully autonomous platform operations. In the coming years, we will see the deep integration of large language models (LLMs) directly within the operational stack, allowing infrastructure engineers to analyze complex system states using natural language and receive instant diagnostic summaries.
We are also advancing beyond simple alert orchestration into an era of true self-healing system frameworks. Future enterprise environments will feature continuous automation systems that can catch security vulnerabilities, predict infrastructure scaling blocks, test safe code fixes inside isolated test environments, and deploy production updates autonomously without requiring human intervention.
As enterprise infrastructure footprints continue to scale out globally, mastering AIOps training ensures you stay at the absolute forefront of this platform management revolution.
Frequently Asked Questions (FAQs)
1.What technical prerequisites are expected before starting an AIOps course?
A foundational understanding of basic IT infrastructure, systems administration, or basic cloud environments is highly useful, but an advanced data science background or deep coding experience is not required.
2.How exactly does an AIOps setup reduce overall notification volume?
By utilizing automated clustering models, the analytics engine groups thousands of scattered, concurrent system alerts into a single, comprehensive incident ticket based on shared timing and topology maps.
3.Is an AIOps strategy intended to replace human engineering teams?
No. It is designed to automate repetitive, low-level triaging tasks and eliminate alert noise, freeing up human operations teams to focus on high-value system design, architecture, and proactive improvements.
4.What is the core difference between observability and traditional system monitoring?
Monitoring tracks whether a system has crossed a predefined, human-configured threshold boundary. Observability allows engineers to infer the deep internal health of a highly complex system by analyzing rich telemetry data, even for entirely novel failure modes.
5.Can I learn AIOps online effectively if I don’t have a background in statistics?
Yes. Structured platforms like AIOpsSchool focus entirely on the practical configuration and orchestration of AI platforms, making it highly accessible for IT professionals without an advanced data science degree.
6.What does behavioral baselining mean inside an intelligent IT workflow?
It is the practice where a machine learning model tracks system metrics over extended historical windows to learn cyclical usage trends, allowing it to dynamically adjust alert boundaries based on the day or hour.
7.How do SRE professionals benefit directly from an AIOps training track?
It equips SRE teams with the precise skills needed to optimize alert configurations, minimize MTTR, manage corporate error budgets effectively, and implement robust self-healing infrastructure patterns.
8.What telemetry data points are analyzed during automated root cause identification?
The platform maps live infrastructure topologies, application dependency maps, code update logs, error frequencies, and detailed timing correlations to isolate a systemic fault.
9.Why do traditional fixed-threshold alerts fail in containerized cloud setups?
Modern microservices are highly ephemeral and scale up and down continuously. Fixed limits trigger constant false-positive alerts during minor, harmless traffic spikes, creating massive alert fatigue for on-call engineers.
10.What primary role does automation play within an analytical AIOps loop?
Automation handles the active response loop. Once the machine learning engine identifies a system issue and isolates the root cause, automation runbooks step in to execute targeted fixes without manual effort.
11.How does an AIOps approach enhance corporate capacity planning?
It leverages time-series predictive regression models to analyze long-term resource usage patterns, letting infrastructure teams scale out systems well before capacity limits affect performance.
12.What is a distributed trace and why is it important to operations?
A distributed trace records the exact end-to-end pathway of a user request as it travels across various microservices, allowing engineers to pinpoint exactly where latency or network bottlenecks occur.
13.Are these advanced analytical patterns useful for traditional on-premises datacenters?
Yes. While highly beneficial for modern cloud platforms, the core concepts of event correlation, log analytics, and anomaly detection apply equally well to legacy and hybrid server environments.
14.How long does it take to complete a formal AIOps foundation program?
Depending on your existing infrastructure experience and the hours you commit to learning each week, most technology professionals complete the coursework and certification prep within a few weeks.
15.What is the direct business advantage of moving toward predictive operations?
It transforms an enterprise from a costly state of constant reactive firefighting to a proactive model where potential system disruptions are mitigated before they can impact end-user transactions.
Final Recommendation
As enterprise software systems grow more complex, traditional approach-and-react operations models are becoming a major liability. Relying on manual troubleshooting and fixed, rigid alerts is a recipe for high stress, alert fatigue, and costly infrastructure outages. Navigating this modern landscape requires transitioning to data-driven, intelligent operations.
There is a massive and growing global demand for engineering professionals who know how to deploy, tune, and manage AI-driven IT operations. Acquiring these specialized skills is one of the most effective ways to future-proof your technology career.