Introduction
Modern IT environments have evolved beyond human scale. The rapid shift toward cloud-native ecosystems, microservices architectures, and highly distributed Kubernetes clusters has generated an unprecedented volume of operational data. Every minute, enterprise infrastructure pumps out millions of logs, metrics, traces, and events. For traditional operations teams, managing this overwhelming sea of data manually is no longer viable. As a result, the global demand for skilled professionals who can design, deploy, and manage these intelligent ecosystems is skyrocketing. Whether you are an individual engineer looking to future-proof your career or an organization attempting to modernize its infrastructure, acquiring comprehensive expertise through structured platforms like AIOpsSchool has become the gold standard for navigating this transformation.
Featured Snippet
What Is AIOps?
AIOps, or Artificial Intelligence for IT Operations, is the application of machine learning, big data, and analytics to automate and improve IT operational processes. It combines multi-layered data ingestion with advanced algorithms to correlate events, detect anomalies, predict performance issues, and accelerate root-cause analysis across complex enterprise infrastructures.
Understanding AIOps
What Is Artificial Intelligence for IT Operations?
At its core, AIOps bridges the gap between massive, unstructured operational data and actionable insights. Instead of relying on static, hardcoded thresholds that frequently trigger false positives, AIOps platforms use mathematical algorithms to understand what “normal” behavior looks like across your entire software delivery pipeline.
Why Traditional IT Operations Are No Longer Enough
Traditional IT operations rely on siloed dashboards where each team monitors its own component—networks, databases, or front-end applications—independently. When a failure happens, these fragmented views prevent teams from seeing the bigger picture. Furthermore, traditional systems cannot scale alongside dynamic microservices that spin up and down in milliseconds.
How AI and Machine Learning Improve Operations
AI shifts IT operations from a reactive posture to a proactive and predictive one. Machine learning models analyze historical telemetry data to identify subtle statistical deviations that human operators would miss. This allows teams to identify degradation patterns early, long before a critical system failure occurs.
Evolution from Monitoring to Intelligent Operations
Monitoring tells you when a system is broken. Observability helps you understand why it is broken. AIOps takes it a step further by showing you how to fix it, or even fixing it autonomously.
| Traditional Operations | AIOps-Driven Operations |
| Reactive: Fixes problems after they cause downtime. | Proactive: Predicts and mitigates anomalies early. |
| Siloed Monitoring: Fragmented views across tools. | Unified Analytics: Single pane of glass for all data. |
| Static Thresholds: Fixed limits cause high alert fatigue. | Dynamic Baselines: AI adapts to changing workloads. |
| Manual Triaging: War rooms spend hours finding issues. | Automated RCA: AI pinpoints root causes instantly. |
Frame of Reference
- In Simple Terms: Imagine your IT system is a massive airport. Traditional monitoring is a security guard staring at 50 different camera screens at once. AIOps is an intelligent system that analyzes every camera feed simultaneously, automatically alerts guards only when a real threat is detected, and predicts where traffic jams will form based on flight schedules.
- Real-World Example: A global logistics provider integrated machine learning models into its API gateway pipeline. When a background database update slowed down API responses by 15%, the AI isolated the exact SQL query mismatch within 90 seconds, preventing a global shipping delay.
- Why It Matters: Moving from monitoring to intelligent operations slashes Mean Time to Resolution (MTTR), protects enterprise revenue, and frees engineering talent from routine firefighting so they can build value-driven software.
- Key Takeaways:
- Siloed, static monitoring tools fail under cloud-native scales.
- Machine learning identifies non-linear anomalies across systems.
- AIOps unifies logs, metrics, and traces into actionable operational intelligence.
Why AIOps Skills Are Becoming Essential
Growth of Cloud-Native Infrastructure
As enterprises migrate to public, private, and hybrid clouds, the perimeter of IT infrastructure is constantly shifting. Engineers must know how to deploy intelligent agents that automatically discover and adapt to changing resources without manual configuration.
Rise of Distributed Systems
Microservices and serverless architectures break applications into thousands of moving parts. Because these parts interact dynamically, tracing a single transaction requires a deep understanding of distributed telemetry and mathematical correlation engines.
Demand for Reliability Engineering
Site Reliability Engineering (SRE) teams are tasked with maintaining high availability while moving at high speeds. AIOps skills provide SREs with the statistical insights needed to manage error budgets, set realistic Service Level Objectives (SLOs), and scale operations linearly.
Automation of Incident Management
The modern enterprise cannot afford manual incident ticketing, routing, and escalation. Knowing how to link AIOps platforms to IT Service Management (ITSM) systems like ServiceNow or Jira Service Management enables zero-touch incident routing and rapid automated remediation.
Future of Autonomous Operations
We are moving rapidly toward self-healing infrastructures. Professionals who master AIOps now will become the architects of autonomous loops where AI detects a problem, provisions a fix, tests the resolution, and documents the incident without human intervention.
Frame of Reference
- In Simple Terms: As technology grows bigger and faster, humans need smart software assistants to help manage the workload. Learning AIOps means learning how to build and control these assistant systems.
- Real-World Example: During a high-profile media streaming event, an automated AIOps pipeline detected a memory leak in a container cluster. The platform automatically applied a rolling restart to affected nodes, preventing a widespread user outage without waking up the on-call engineer.
- Why It Matters: Organizations with AIOps-trained teams experience dramatically fewer operational outages and can deploy software faster, capturing a clear competitive advantage in digital markets.
- Key Takeaways:
- Distributed systems are too complex for human-only management.
- AIOps skills bridge the operational gaps in DevOps, SRE, and platform engineering.
- Mastering automated remediation positions you at the forefront of the autonomous cloud era.
AIOps Certification Explained
What Is an AIOps Certification?
An AIOps certification is a professional validation that proves an engineer understands how to deploy machine learning algorithms, ingest large-scale operational datasets, configure automated alerting pipelines, and interpret AI-driven root cause analyses within enterprise infrastructures.
Benefits of Professional Certification
A structured certification validates your expertise to employers, setting you apart in a crowded tech landscape. It demonstrates that you don’t just understand basic monitoring tools, but that you know how to build comprehensive, data-driven observability architectures.
Skills Validated Through Certification
- Statistical anomaly detection and machine learning model selection for time-series data.
- Configuration of advanced event correlation engines.
- Integration of open-source observability frameworks like OpenTelemetry.
- Implementation of self-healing scripts and automated remediation patterns.
Who Should Pursue AIOps Certification?
- DevOps Engineers looking to inject automated intelligence into their CI/CD and deployment pipelines.
- SRE Engineers aiming to automate incident management and protect strict error budgets.
- Cloud & Platform Engineers designing self-healing, highly resilient infrastructure foundations.
- Monitoring Specialists transitioning from traditional alert systems to modern observability setups.
- IT Managers & Leaders who need to oversee enterprise-wide operational transformations.
Frame of Reference
- In Simple Terms: A certification is like a driver’s license for complex enterprise AI systems. It proves to companies that you can safely and effectively run their automated operations center.
- Real-World Example: A systems engineer completed an industry-aligned certification program. Within three months, they used their skills to lead a legacy monitoring migration project, securing a promotion to Principal Reliability Architect.
- Why It Matters: Certifications establish clear educational benchmarks, ensuring that engineers possess the practical, standardized skills required to execute complex digital transformations successfully.
- Key Takeaways:
- Certification proves a deep mastery of operational data science and system observability.
- It provides an immediate career differentiator for engineers working in DevOps and cloud platforms.
- Certified teams ensure lower deployment risks during large-scale digital transformations.
AIOps Training and Courses
To succeed in this domain, your training should cover both theoretical machine learning principles and hands-on system engineering. High-quality training programs focus on several core disciplines:
Machine Learning for IT Operations
Learners explore supervised and unsupervised learning algorithms optimized for IT infrastructure. This includes time-series forecasting to predict capacity overloads and clustering techniques to group similar error messages together.
Event Correlation
This discipline teaches you how to map hundreds of scattered alerts occurring across different systems into a single, cohesive incident context, stripping away operational noise.
Intelligent Alerting
Instead of setting static alert thresholds, you learn how to configure dynamic baseline alerts that automatically adjust based on historical factors, such as day of the week or time of day.
Root Cause Analysis (RCA)
Training centers on how AI uses topology mapping and dependency graphs to trace a failure back to its originating code commit, database query, or network switch.
Predictive Analytics
Engineers learn to leverage historical trends to predict hardware degradation, software deadlocks, or bandwidth exhaustion hours before they manifest.
[Raw Operational Data] ---> [Inference Engine] ---> [Correlated Incidents] ---> [Automated Fix]
Incident Automation
This maps out how to construct event-driven playbooks that trigger specific code scripts (such as scaling out a cluster or purging a cache) the moment an anomaly is verified.
Observability & OpenTelemetry
Courses teach students how to standardize telemetry collection using OpenTelemetry, avoiding vendor lock-in and creating a clean data stream for AI processing.
Monitoring Automation
Learners understand how to use Infrastructure as Code (IaC) to automatically deploy monitoring agents and log shippers alongside every new cloud resource.
AIOps Engineer Certification Path
To successfully transition into this field, professionals should follow a structured learning path that balances basic foundational concepts with advanced implementation skills.
| Level | Skills Learned | Professional Outcome |
| Beginner | Linux, Python, Basic Telemetry (Logs/Metrics), Core Monitoring Principles. | Competent to assist in monitoring maintenance and basic dashboard configuration. |
| Intermediate | OpenTelemetry, Event Clustering, Anomaly Detection, ITSM Integration. | Capable of designing distributed tracking and configuring intelligent alerting engines. |
| Advanced | Custom ML Model Selection, Multi-cloud Topology Mapping, Automated Self-Healing Runbooks. | Qualified to architect enterprise-wide AIOps deployments and lead infrastructure transformations. |
Frame of Reference
- In Simple Terms: You start by learning how to collect data, advance to using AI to understand the data, and finish by creating systems that fix problems completely on their own.
- Real-World Example: An enterprise engineering division mapped their teams to this structured path over 12 months. This systematic training approach led to a 40% reduction in high-priority incident tickets within their core applications.
- Why It Matters: A structured, tiered learning path prevents engineers from feeling overwhelmed by the vast scope of data science and cloud engineering.
- Key Takeaways:
- Foundations require a mix of core systems engineering and basic scripting.
- Intermediate steps focus heavily on standardizing your data with OpenTelemetry.
- Advanced mastery culminates in building reliable, event-driven self-healing workflows.
AIOps Engineer Career Roadmap
Required Technical Skills
To build a resilient career as an AIOps engineer, you need a diverse toolkit across several foundational technology domains:
- Linux & Networking: Deep knowledge of operating system internals, kernel parameters, and network topologies (TCP/IP, DNS, BGP) to understand where system bottlenecks occur.
- Cloud Platforms & Kubernetes: Hands-on experience managing infrastructure across major cloud environments (AWS, Azure, GCP) and configuring orchestration platforms like Kubernetes.
- Monitoring Tools: Familiarity with ecosystem components such as Prometheus, Grafana, Datadog, or Dynatrace.
- Automation & Scripting: Strong coding skills in Python, Go, or Bash to construct automations, manipulate data structures, and interact with complex platform APIs.
- Observability Frameworks: Mastery of open-source frameworks, with a particular focus on OpenTelemetry standards for extracting high-cardinality telemetry.
Learning Sequence
- Master Systems Engineering: Become proficient with Linux systems, cloud networking, containerization, and basic infrastructure provisioning.
- Implement Traditional Monitoring: Learn how to configure standard metrics collection, centralized log management, and baseline dashboards.
- Adopt OpenTelemetry Standards: Transition from vendor-specific monitoring agents to open, vendor-agnostic data collection frameworks for logs, metrics, and distributed traces.
- Apply Statistical Analytics & AI: Study how algorithms perform anomaly detection, group related events, and analyze historical time-series data.
- Develop Automated Remediation Pipelines: Connect your AI insights directly to automation platforms, writing reliable playbooks that safely resolve incidents automatically.
AI Observability Training
What Is AI Observability?
AI Observability is the practice of tracking, analyzing, and explaining the inner workings of complex distributed systems by applying artificial intelligence to comprehensive telemetry data. Unlike standard monitoring, which only tracks known failure points, AI Observability uncovers hidden patterns and systemic regressions that you didn’t even know to look for.
Why Observability Matters
Modern distributed systems change constantly. With microservices updating continuously throughout the day, static dashboards become obsolete almost immediately. Observability provides the rich data foundation that AI engines need to accurately map dependencies and trace real-time system behaviors.
Logs, Metrics, Traces, and Events (MELT)
The cornerstone of any observability strategy is the ingestion of high-fidelity data types:
- Metrics: Numerical values measuring system performance over time (e.g., CPU utilization, error rates).
- Logs: Text records detailing specific code events or system exceptions at precise timestamps.
- Traces: End-to-end paths showing exactly how a transaction journeys through an interconnected web of microservices.
- Events: Significant structural changes within the ecosystem, such as code deployments, auto-scaling events, or configuration updates.
OpenTelemetry Fundamentals
OpenTelemetry (OTel) provides a unified, open-source standard for collecting, processing, and exporting telemetry data. By mastering OTel, engineers ensure their AI engines receive clean, structured, and contextual data inputs without getting locked into proprietary vendor ecosystems.
Intelligent Monitoring Systems
By applying artificial intelligence directly to your telemetry pipelines, monitoring setups can dynamically update alerting rules, correlate patterns across different data streams, and spotlight emerging architectural regressions in real time.
| Monitoring | Observability |
| Tracks predefined metrics based on known failure points. | Explores system behaviors to explain novel, unexpected issues. |
| Uses static thresholds that require ongoing manual tuning. | Leverages dynamic baselines that automatically adapt to workloads. |
| Tells you when a specific component breaks. | Explains why a complex, distributed interaction failed. |
| Operates within component siloes (infrastructure vs. app). | Cross-references logs, traces, and metrics into a unified context. |
Frame of Reference
- In Simple Terms: Monitoring is like checking your car’s dashboard light to see if the engine is overheating. Observability is using an advanced diagnostic scanner that tracks real-time fuel mixtures, internal pressures, and exhaust values to show you exactly why the engine is running hot.
- Real-World Example: A fintech application experienced intermittent payment drop-offs. Traditional monitoring dashboards showed all green because CPU and memory levels were healthy. AI Observability traced an isolated database deadlock occurring only when international users utilized specific payment combinations.
- Why It Matters: Implementing AI-driven observability ensures you capture high-cardinality data, giving your teams the deep visibility required to track down elusive microservices regressions.
- Key Takeaways:
- High-quality AIOps depends entirely on clean, well-structured observability data.
- OpenTelemetry is the global industry standard for modern, open data ingestion.
- True observability shifts operations from tracking symptoms to fully explaining complex system behaviors.
AIOps for SRE and DevOps Engineers
How AIOps Supports SRE Practices
Site Reliability Engineering focuses heavily on automation, maintaining system availability, and managing error budgets. AIOps platforms act as an operating system for SREs, handling routine maintenance, accelerating incident triaging, and providing objective analytics to help teams balance feature velocity with platform stability.
Reducing Alert Fatigue
One of the largest drains on engineering morale is alert fatigue—getting flooded with thousands of low-priority, duplicate notification pings daily. AIOps platforms analyze these alert storms, filter out the noise, and group related warnings into a single, comprehensive incident dossier. This ensures on-call engineers are only paged for issues that genuinely require human attention.
[500 Network Alerts] + [300 App Errors] ---> [AIOps Engine] ---> One Single Actionable Incident
Improving Incident Response
When a production issue strikes, AIOps accelerates the incident response lifecycle. Instead of gathering engineers in an emergency war room to dig through logs manually, the AI instantly provides the blast radius, highlights the most likely root causes, and suggests proven remediation steps.
Enhancing Reliability Engineering
By leveraging historical trends and predictive capacity modeling, engineering teams can identify code bottlenecks, database scaling constraints, and memory regressions before their production systems experience actual service degradations.
Supporting Continuous Delivery
Integrating operational AI insights back into CI/CD pipelines lets teams catch performance drops right after a code push. If an AIOps model flags a spike in error rates immediately following a microservice update, it can automatically trigger a canary rollback, preserving platform reliability.
Frame of Reference
- In Simple Terms: AIOps acts like an intelligent co-pilot for SRE and DevOps engineers, taking care of noisy alerts and routine diagnostic steps so humans can focus on building features and refining architecture.
- Real-World Example: An enterprise tech company integrated an incident intelligence engine into their DevOps workflow. The platform grouped 1,200 chaotic daily alerts into 5 clear incidents, reducing their overall MTTR from 4 hours down to just 11 minutes.
- Why It Matters: Protecting your engineers from alert fatigue directly reduces burnout, helps teams maintain strict SLA targets, and optimizes operational efficiency.
- Key Takeaways:
- AIOps eliminates repetitive alert noise, helping engineers focus on real, actionable issues.
- Automated root cause analysis drastically reduces time spent in emergency incident war rooms.
- Connecting AI insights to your CI/CD pipelines enables safer, faster software deployment loops.
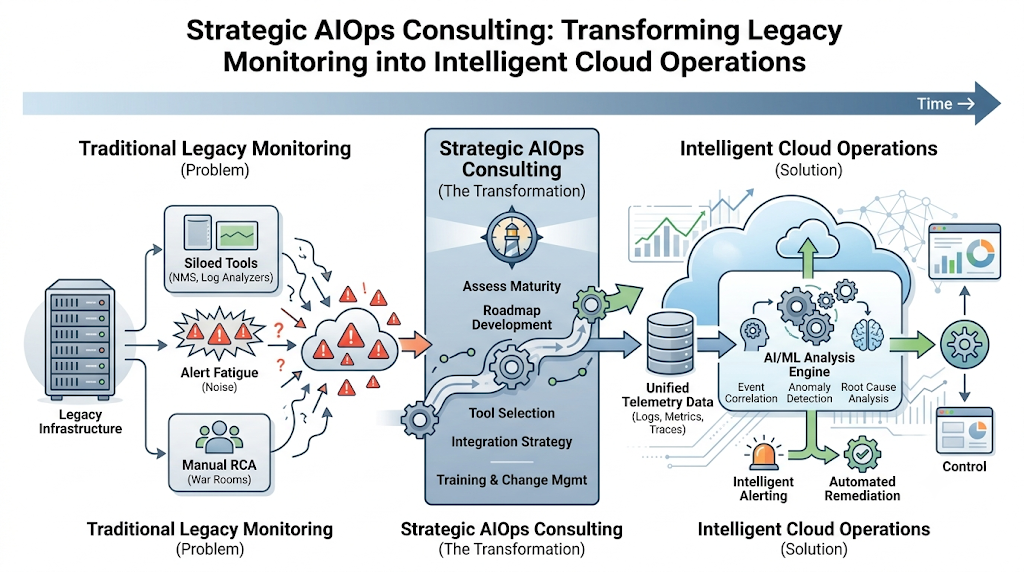
Enterprise AIOps Consulting
Why Organizations Need AIOps Consulting
Transitioning a large enterprise over to an AI-driven operational model involves navigating complex architecture choices, cultural changes, and tool integrations. Strategic AIOps consulting provides organizations with the expert guidance needed to avoid costly false starts, choose the right technology investments, and align their operational workflows with long-term business goals.
Assessing Operational Maturity
Before writing any automation scripts or purchasing platforms, consultants evaluate an enterprise’s existing technical capabilities. This assessment helps map out data cleanliness, tool fragmentation, team skills, and overall observability readiness.
[Level 1: Siloed Monitoring] -> [Level 2: Unified Telemetry] -> [Level 3: Predictive AI] -> [Level 4: Autonomous Operations]
Tool Selection Strategies
The market is filled with an array of monitoring, observability, and AI tools. AIOps consultants help enterprises evaluate these options objectively, choosing solutions that match their technical scale and integrate smoothly with existing tech stacks.
Building AIOps Roadmaps
A successful rollout requires a phased implementation roadmap. Consultants help teams prioritize high-impact, manageable goals first—such as alert noise reduction—before moving on to advanced objectives like automated self-healing workflows.
Change Management Considerations
Shifting to automated systems requires built-in organizational trust. Consulting frameworks focus heavily on upskilling teams, establishing transparent automation guardrails, and shifting culture from traditional firefighting to proactive engineering.
Frame of Reference
- In Simple Terms: AIOps consulting is like hiring an experienced sherpa to guide your company up a steep, unfamiliar mountain. They help you pick the right gear, choose the safest path, and avoid common structural pitfalls.
- Real-World Example: A Fortune 500 insurance firm partnered with enterprise consultants to modernize their legacy operations center. The resulting structured roadmap helped them safely decommission 14 redundant monitoring tools, saving over $2 million in licensing fees alone.
- Why It Matters: Specialized consulting minimizes deployment risks, ensures technology investments deliver clear business value, and prepares your workforce for the future of automated operations.
- Key Takeaways:
- Successful AIOps adoption requires a clear, objective assessment of your current data maturity.
- Phased deployment roadmaps build team trust and deliver steady, measurable return on investment.
- Active change management is essential for breaking down traditional operational silos.
AIOps Implementation Services
Bringing an AIOps strategy to life requires executing a highly structured lifecycle that transforms raw engineering environments into smart, self-healing systems.
[1. Assessment] ---> [2. Design] ---> [3. Integration] ---> [4. Automation] ---> [5. Optimization]
1. Assessment
Engineers inspect the entire data footprint, reviewing existing logs, metrics, and tracing pipelines to verify that the incoming data stream is clean and complete enough to train AI models effectively.
2. Design
Architects create a unified blueprint for data ingestion, defining data governance parameters, mapping out system dependencies, and planning where core correlation engines will live.
3. Tool Integration
Implementation teams connect data collection pipelines to central AI engines using secure APIs and open-source collectors, establishing a clear, single pane of glass across the infrastructure.
4. Automation Playbooks
Engineers construct secure, event-driven webhooks and orchestration runbooks that hook directly into platform endpoints, enabling instant responses to verified infrastructure incidents.
5. Optimization & Fine-Tuning
Teams continuously monitor model performance, tweaking anomaly thresholds and adjusting machine learning parameters to minimize false positives and maximize root cause accuracy.
6. Continuous Improvement
Operational workflows are regularly updated with new telemetry data sources, evolving system patterns, and refined automated scripts to keep pace with changing software deployments.
Frame of Reference
- In Simple Terms: Implementation services take your technical roadmap and actually build it—installing data connections, configuring the AI brain, and setting up automated responses.
- Real-World Example: A retail banking platform utilized specialized implementation services to deploy an end-to-end incident automation workflow. The system safely resolved high-frequency disk space and cache issues automatically, reducing manual infrastructure tickets by 65%.
- Why It Matters: Following a comprehensive, structured implementation lifecycle ensures your platform configurations remain highly reliable, secure, and easily maintainable as your architecture grows.
- Key Takeaways:
- Clean data ingestion is the essential foundation for any automation architecture.
- Playbooks must be built with clear human-in-the-loop controls to establish operational trust.
- Regular optimization keeps machine learning models accurate and fully aligned with system changes.
Real-World Enterprise Use Cases
Banking and Financial Services
- Operational Challenge: A major retail bank suffered from intermittent transaction failures during high-volume processing windows, risking regulatory penalties and damaging customer trust.
- AIOps Solution: The bank deployed an real-time event correlation engine that analyzed database locks alongside transaction network spikes.
- Business Outcome: The platform cut root cause identification time from hours down to under 3 minutes, preserving payment reliability and protecting core financial compliance metrics.
Healthcare Platforms
- Operational Challenge: A distributed telemedicine network faced severe latency spikes across patient portals, making it difficult for physicians to access critical health records.
- AIOps Solution: Teams implemented an AI observability framework using OpenTelemetry to map data processing flows across multiple cloud environments.
- Business Outcome: The system automatically identified an unindexed database query in a secondary microservice, allowing developers to patch the bug before it impacted patient care channels.
SaaS Companies
- Operational Challenge: A high-growth B2B enterprise software company suffered from severe alert fatigue, with on-call engineers facing over 2,000 automated system alerts every week.
- AIOps Solution: They implemented an intelligent incident filtering system that grouped redundant alerts into unified, contextual cases.
- Business Outcome: On-call alerts dropped by 85%, significantly reducing developer burnout and allowing engineering teams to dedicate more time to core feature innovation.
Telecommunications
- Operational Challenge: A global telecom carrier faced frequent cell tower disconnects caused by unpredicted hardware degradation and localized power fluctuations.
- AIOps Solution: Technicians deployed predictive time-series forecasting models to monitor signal qualities and equipment temperatures.
- Business Outcome: The operations team successfully shifted to a proactive maintenance model, fixing vulnerable hardware components before actual service outages affected customers.
E-Commerce Platforms
- Operational Challenge: An e-commerce marketplace experienced major cart checkout drop-offs during a global holiday promotion, leading directly to lost revenue.
- AIOps Solution: An automated incident intelligence solution instantly isolated a broken third-party payment gateway integration.
- Business Outcome: The platform automatically rerouted cart checkouts through an alternative payment processor, saving millions in potential lost sales.
Benefits of AIOps Adoption
Implementing an AI-driven operations strategy brings widespread improvements across an entire organization:
- Drastically Reduced Downtime: By identifying and resolving potential system errors early, companies protect critical production environments from costly service outages.
- Rapid Root Cause Analysis (RCA): Machine learning models quickly parse through massive datasets, pointing engineers directly to the source of an issue instead of forcing them to sift through logs manually.
- Enhanced User Experience: Consistently high platform availability and fast response times translate directly into higher user satisfaction and stronger customer retention.
- Optimized Operational Costs: Consolidating redundant monitoring tools and automating routine tasks significantly lowers software licensing costs and trims operational overhead.
- Improved System Reliability: Proactive infrastructure tracking helps engineering teams systematically surface and eliminate hidden architectural weaknesses over time.
- Data-Driven Decision Making: Leadership teams gain access to clear, comprehensive operational analytics, making it easier to plan infrastructure investments and map out future product capacity.
Common Challenges in AIOps Adoption
While the advantages are clear, scaling an AIOps strategy requires managing a few common technical and organizational hurdles:
- Data Quality and Siloes: AI models need clean, well-structured telemetry data to work effectively. If an enterprise’s data is siloed across disconnected tools, the AI cannot generate accurate insights.
- Solution: Standardize all infrastructure telemetry data collection using OpenTelemetry frameworks to establish a clean, unified data stream.
- Complex System Integrations: Connecting new AI platforms to legacy enterprise monitoring systems can be tricky and time-consuming.
- Solution: Work with experienced consultants to build a phased integration map that connects core operational systems one step at a time.
- The Technical Skills Gap: Many engineering teams lack the combined knowledge of systems operations, distributed observability, and data science required to manage modern platforms.
- Solution: Sponsor comprehensive training and industry certifications for your internal teams through specialized educational providers.
- Organizational Resistance: Operations teams are often hesitant to trust automated scripts to make critical fixes in production environments.
- Solution: Implement automations with built-in human-in-the-loop approvals first, fully automating the fixes only after the scripts have proven reliable over time.
- Low Observability Maturity: Attempting to roll out advanced predictive AI workflows before you have basic telemetry data collection in place often leads to inaccurate insights and project delays.
- Solution: Focus on building solid log management and distributed tracing foundations before rolling out advanced machine learning models.
Common Mistakes Professionals Make
Avoid these frequent pitfalls when building out your personal skills or designing an enterprise implementation strategy:
- [ ] Focusing Only on Tools: Buying expensive platform licenses without training your engineers on underlying data models or observability concepts.
- [ ] Ignoring Observability Fundamentals: Attempting to implement machine learning analytics on top of messy, low-quality log data and incomplete traces.
- [ ] Poor Infrastructure Data Collection: Missing crucial context by failing to track configuration updates, code deployments, or cloud topology maps.
- [ ] Skipping the Automation Strategy: Finding anomalies with AI but still relying on slow, manual engineering pipelines to fix them.
- [ ] Neglecting Continuous Learning: Failing to keep up with fast-evolving cloud-native tools, open telemetry standards, and modern event-driven runbooks.
Future of AIOps
As technology continues to advance, the discipline of AI-driven operations is evolving rapidly across several major horizons:
Autonomous Self-Healing Infrastructure
We are moving beyond basic alerting and simple automation scripts. The future belongs to completely self-healing architectures where AI models dynamically provision additional cloud capacity, reroute network traffic around outages, apply hot-fixes to application code, and test system stability on the fly without requiring human intervention.
GenAI-Powered Incident Management
Generative AI and Large Language Models (LLMs) are transforming how engineers interact with operational systems. In the near future, on-call operators will query their infrastructure using everyday natural language, receiving instant code explanations, interactive dependency maps, and automatically generated post-mortem incident reports.
Predictive Reliability Engineering
Instead of reviewing system errors after they occur, machine learning models will continuously simulate production traffic loads, software configurations, and third-party integrations to spotlight architectural vulnerabilities before a single line of code goes live.
Why Learn with AIOpsSchool
Navigating this rapidly evolving technical landscape requires a structured, hands-on educational approach. AIOpsSchool provides specialized training programs carefully designed to bridge the gap between traditional operations and modern AI-driven architectures.
- Industry-Aligned Curriculum: Courses are engineered by active enterprise consultants, ensuring you study the exact technologies and strategies in high demand across the tech sector.
- Hands-on Production Labs: Move beyond passive video watching by building, testing, and debugging real-world data pipelines, anomaly detection engines, and automated self-healing workflows inside live sandboxed cloud environments.
- Professional Certification Programs: Earn recognized career credentials that validate your expertise in distributed system observability, event correlation, and advanced incident automation.
- Enterprise Transformation Consulting: Learn from specialists who actively design and execute large-scale digital transformations for global enterprises, giving you access to real-world deployment playbooks.
- Career-Oriented Skill Advancement: Transition smoothly into lucrative high-demand roles like SRE Mentor, DevOps Leader, or Platform Architect by mastering the intersection of data science and systems engineering.
FAQ SECTION
1. What is AIOps Certification?
An AIOps certification is an industry-recognized professional credential that verifies an engineer’s practical ability to combine machine learning algorithms, big data, and modern observability practices to automate and streamline IT operations.
2. Who should learn AIOps?
DevOps engineers, Site Reliability Engineers (SREs), cloud infrastructure architects, platform engineers, monitoring specialists, and technology managers looking to automate large-scale systems and build intelligent infrastructure ecosystems should learn AIOps.
3. What skills are required for AIOps Engineers?
A successful engineer needs a strong foundation in Linux systems, cloud platforms (AWS, Azure, or GCP), container orchestration (Kubernetes), programming/scripting (Python or Go), distributed tracing telemetry, and open-source data standards like OpenTelemetry.
4. How does AIOps help DevOps teams?
AIOps assists DevOps teams by filtering out redundant alert noise, automating incident triaging, speeding up root cause analysis, and integrating smart performance checkpoints directly into continuous deployment pipelines.
5. What is AI Observability?
AI Observability is the practice of tracking and explaining complex system behaviors by applying machine learning algorithms to comprehensive, real-time datasets consisting of logs, metrics, traces, and operational events.
6. What is OpenTelemetry?
OpenTelemetry is an open-source, vendor-agnostic framework designed to standardize how applications generate, collect, and export telemetry data (logs, metrics, and traces), ensuring clean data streams for AI analytical tools.
7. How long does it take to learn AIOps?
For engineers who already possess a solid background in basic cloud systems and scripting, it typically takes 3 to 6 months of dedicated study to master core AI observability platforms and automated remediation workflows.
8. What are AIOps Implementation Services?
These are specialized enterprise professional services focused on designing data ingestion architectures, integrating distributed observability tooling, configuring machine learning engines, and constructing reliable self-healing workflows within live production environments.
9. Is AIOps a good career choice?
Yes, it is an excellent career choice. As enterprise IT environments grow increasingly complex, the demand for certified talent who understand how to deploy intelligent automations and manage data-driven reliability ecosystems continues to rise rapidly.
10. What is the future of AIOps?
The future centers around fully autonomous self-healing cloud infrastructures, natural-language operational interfaces driven by Generative AI, and predictive reliability platforms that stop system incidents before they can impact production environments.
FINAL SUMMARY
The scale of modern cloud-native software has outpaced manual human management. To maintain system reliability and sustain high deployment speeds, mastering the tools and strategies of AI-driven operations is no longer optional—it is a core business and career requirement.
Investing in structured education, hands-on courses, and professional certifications through platforms like AIOpsSchool equips engineers with the exact technical skills required to lead modern engineering teams. Simultaneously, leveraging strategic enterprise consulting and structured implementation services allows organizations to eliminate operational noise, slash system downtime, and transition their legacy setups into high-performance, autonomous operations.