Today, most companies use cloud, containers, and microservices to run their applications. These systems are powerful, but they are also complex and hard to understand from the outside. Simple server monitoring or a few dashboards are no longer enough to see what is going wrong. Observability engineering helps you see deep inside your system so you can find, fix, and prevent problems faster. Master in Observability Engineering (MOE) is a certification program that teaches you how to design and run observability for real production systems. It is made for working professionals like DevOps Engineers, SREs, Platform Engineers, and Engineering Managers. In this guide, you will learn what MOE is, who it is for, what skills you gain, how to prepare, and how it fits into your career plan. The language is simple so that busy engineers and managers can understand and act on it quickly.
Why Observability Engineering Is Important
Modern systems are:
- Distributed across many services, servers, and clouds.
- Highly dynamic because of autoscaling, containers, and frequent deployments.
- Critical for business, because downtime directly hits revenue and brand.
With such systems, simple checks like CPU usage or a basic log file are not enough. Observability engineering gives you:
- Deep visibility into how your services behave under real user traffic.
- Faster understanding of where a problem is happening and why it started.
- Better support for SRE, DevOps, security, and business decision‑making.
When you have strong observability, you can:
- Detect problems before customers see them.
- Reduce mean time to detect (MTTD) and mean time to resolve (MTTR).
- Improve reliability, performance, and user satisfaction over time.
MOE Certification Overview
The MOE program is an advanced‑level certification with hands‑on labs. It takes you from basic ideas to full observability design in a step‑by‑step way. The training is usually delivered through online or blended sessions, with exercises and projects.
Main topic areas include:
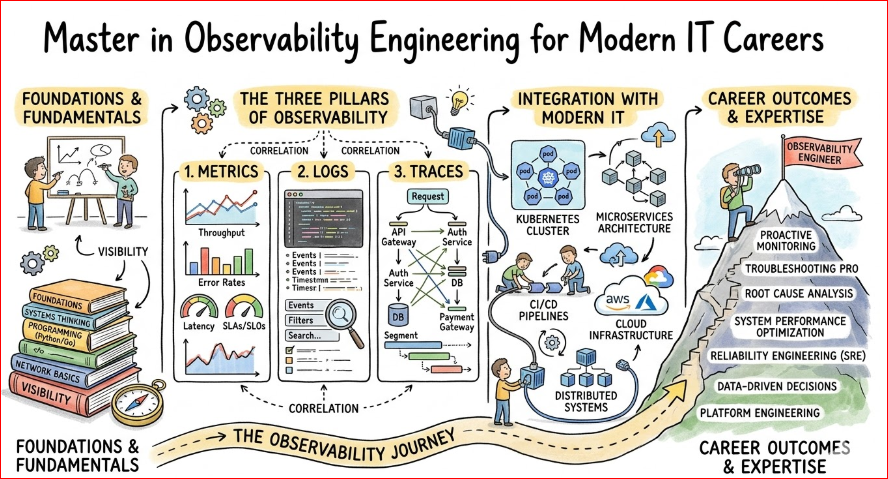
- Fundamentals: monitoring vs observability, telemetry, and key terms.
- Signals: metrics, logs, traces, events, and how to use each one.
- Tools: Prometheus, Grafana, ELK stack, Jaeger, and similar platforms.
- OpenTelemetry: collecting and exporting data from services in a standard way.
You also work on:
- Alerting, on‑call, and incident management flows.
- Observability for Kubernetes, microservices, and APIs.
- Cost control, sampling, and data retention planning so you do not overspend.
MOE Certification Table
| Track | Level | Who it’s for | Prerequisites | Skills covered | Recommended order |
|---|---|---|---|---|---|
| Master in Observability Engineering (MOE) | Advanced | DevOps Engineers, SREs, Platform & Cloud Engineers, Security Engineers, Data Engineers, Engineering Managers | Basic Linux, scripting, cloud basics, SDLC; some container/microservices knowledge is helpful | Observability basics, metrics/logs/traces, OpenTelemetry, Prometheus, Grafana, ELK, Jaeger, alerting, incident response, SLO/SLI, CI/CD integration, cost control | After DevOps/Cloud/SRE fundamentals, before deep SRE/AIOps/security specializations |
About Master in Observability Engineering (MOE)
What it is
Master in Observability Engineering (MOE) is a complete program that teaches you how to design and manage observability for modern systems. It shows you how to set up metrics, logs, and traces, and how to use them to find and fix issues. The focus is on simple concepts, strong practice, and useful skills you can use at work from day one.
Who should take it
This certification is designed for working professionals who deal with live systems and care about reliability:
- DevOps Engineers and SREs
They handle CI/CD pipelines, deployments, uptime, and incidents.
MOE helps them get clear data during incidents and after changes.
It also supports SLOs and error budget decisions. - Platform and Cloud Engineers
They manage Kubernetes clusters, cloud workloads, and internal platforms.
MOE helps them standardize telemetry across many services and environments.
It makes platform issues easier to detect and debug. - Security Engineers and DevSecOps professionals
They need visibility into runtime behavior, attacks, and anomalies.
MOE gives them the tools to see patterns and unusual signals.
This helps with faster detection and investigation of security events. - Data Engineers and DataOps professionals
They manage data pipelines, warehouses, and streaming systems.
MOE helps them monitor data quality, latency, and pipeline health.
It reduces surprises in downstream reports and models. - Engineering Managers and Tech Leads
They are responsible for team performance and system reliability.
MOE helps them understand what “good observability” looks like.
They can then guide their teams and set the right priorities.
Skills you’ll gain
By the end of MOE, you should have a solid set of practical skills:
- Observability fundamentals
You will understand the difference between monitoring and observability.
You will learn the three main pillars: metrics, logs, and traces.
You will know where each pillar is most useful. - Telemetry design
You will learn how to decide what to measure and what to log.
You will design meaningful metrics and logging strategies.
You will avoid collecting useless or duplicate data. - OpenTelemetry usage
You will learn how to instrument applications using OpenTelemetry SDKs.
You will work with collectors and exporters to send data to backends.
You will understand how to integrate it into existing codebases. - Tool setup and operations
You will practice with tools like Prometheus, Grafana, ELK, and Jaeger.
You will learn how to install, configure, and manage these systems.
You will build useful dashboards and visualizations. - Alerting and incident workflows
You will design alert rules that are meaningful and not noisy.
You will connect alerts to on‑call rotations and runbooks.
You will practice a simple, repeatable way to handle incidents. - Root cause analysis and performance tuning
You will learn how to use traces and metrics to find bottlenecks.
You will be able to spot slow services, failing dependencies, and hot paths.
You will use this information to make systems faster and more stable. - Cost and data management
You will understand how telemetry affects storage and cloud bills.
You will learn to set retention periods and sampling rates.
You will design a balance between useful data and cost control.
Real-world projects you should be able to do after it
After completing MOE, you should feel confident taking on projects like:
- Designing an observability stack for a microservices app
You can choose tools and set up metrics, logs, and traces.
You can define key service‑level indicators (SLIs) and dashboards.
You can ensure each service has basic instrumentation. - Rolling out OpenTelemetry to existing services
You can plan how to add instrumentation step by step.
You can configure collectors to route data to different tools.
You can avoid breaking changes while adding telemetry. - Building Grafana dashboards for business and technical views
You can design dashboards that show latency, errors, and throughput.
You can add business metrics like orders per minute or active users.
You can arrange panels so that teams can quickly see what matters. - Setting up alerting and on‑call for production
You can define threshold‑based and SLO‑based alerts.
You can connect alerts to messaging or on‑call tools.
You can create simple runbooks so responders know what to do. - Running post‑incident reviews using observability data
You can use traces and logs to reconstruct an incident timeline.
You can identify which service or change caused the issue.
You can propose improvements backed by data. - Optimizing observability cost and retention
You can review which data is actually being used.
You can adjust sampling and retention for each type of data.
You can explain trade‑offs between cost and detail.
Preparation plan
7–14 days fast‑track
This is for people already working in DevOps, SRE, or cloud:
- Day 1–2
Revise Linux, basic networking, and container concepts.
Review how your current systems are monitored today.
Note down gaps or pain points in your current setup. - Day 3–4
Read about observability basics and main ideas.
Learn what metrics, logs, and traces are and why they matter.
Watch simple demos or tutorials to see them in action. - Day 5–7
Pick one tool stack, such as Prometheus + Grafana + Jaeger.
Set it up locally or in a small cloud environment.
Connect a demo or sample app and build a few dashboards. - Day 8–10
Learn OpenTelemetry basics: SDK, collector, exporters.
Add simple instrumentation to one or two services.
Send traces and metrics to your chosen backend. - Day 11–14
Practice writing alert rules and setting up simple incidents.
Simulate a few failures and use your observability data to debug.
Review all topics and list areas where you need more clarity.
30 days structured plan
This suits busy professionals who want a steady pace:
- Week 1 – Concepts and foundations
Spend time understanding observability principles.
Compare traditional monitoring and modern observability.
Learn about SLIs, SLOs, and error budgets at a basic level. - Week 2 – Tools and hands‑on practice
Install and explore Prometheus, Grafana, ELK, and Jaeger (or similar).
Practice writing queries, visualizing metrics, and exploring logs.
Connect at least one simple application end‑to‑end. - Week 3 – Advanced use cases
Focus on Kubernetes and microservices scenarios.
Learn how to observe service mesh traffic if your stack uses it.
Practice tracing requests across several services. - Week 4 – Design, cost, and mock assessment
Design an observability architecture for a sample system.
Plan retention, sampling, and cost control.
Take mock quizzes or practice questions to check your readiness.
60 days in‑depth plan
This is ideal if you are new to observability or want strong depth:
- First 30 days
Follow the 30‑day plan but with more reading and labs.
Spend extra time on topics you find hard, like tracing or OpenTelemetry.
Document what you learn in simple notes or diagrams. - Next 30 days
Choose one realistic project, such as a microservices sample app.
Design and build a complete observability setup for it.
Simulate incidents, performance issues, and capacity problems, and practice handling them.
Common mistakes
Many learners and teams make similar mistakes when starting with observability:
- Thinking it is only about dashboards
They add many charts but do not design good signals.
This leads to pretty screens that do not help in real incidents. - Collecting too much data
They log everything and keep all metrics forever.
Costs go up, queries become slow, and teams feel lost in noise. - Ignoring traces
They focus only on metrics and logs, and skip tracing.
This makes it hard to see how a request flows across services. - No standard for instrumentation
Each team logs and measures things in their own style.
It becomes hard to compare data and build shared dashboards. - No incident practice
Teams never run game days or test their observability.
During real incidents, people are unsure what to look at or how to respond.
Best next certification after this
After MOE, you can move in different directions depending on your goals:
- Same track (deep reliability)
Take advanced SRE or reliability engineering certifications.
Focus on SLO design, error budgets, chaos engineering, and resilience patterns. - Cross‑track (data and AI)
Take AIOps or MLOps certifications.
Learn how to use observability data for anomaly detection and intelligent automation. - Leadership (management and strategy)
Take DevOps or SRE leadership and engineering management programs.
Learn how to build teams, processes, and culture around observability and reliability.
Choose Your Path – 6 Learning Paths
1. DevOps Path
- Start with general DevOps and CI/CD basics.
- Add MOE to make every environment observable from dev to prod.
- Move into platform engineering or DevOps architect roles over time.
2. DevSecOps Path
- Learn secure SDLC, security tools, and DevSecOps concepts.
- Use MOE to get clear security‑related signals from runtime systems.
- Aim for roles that connect security, operations, and development.
3. SRE Path
- Study SRE principles like SLOs, SLIs, and incident response.
- Use MOE to build the observability backbone that SRE needs.
- Grow into senior SRE or Reliability Architect positions.
4. AIOps/MLOps Path
- Learn how ML models are trained, deployed, and monitored.
- Use MOE to collect high‑quality telemetry for AIOps platforms.
- Work on projects like smart alerting and automatic remediation.
5. DataOps Path
- Learn DataOps practices for data pipelines and platforms.
- Use MOE to monitor data quality, delays, and failures.
- Grow into roles managing reliable, large‑scale data systems.
6. FinOps Path
- Learn how cloud costs are tracked and optimized.
- Use MOE to see how observability tools and data affect bills.
- Take roles where you balance reliability with cost control.
Role → Recommended Certifications
| Role | How MOE helps | Suggested order including MOE |
|---|---|---|
| DevOps Engineer | Improves visibility across CI/CD and infra | DevOps basics → Cloud associate → MOE → Advanced DevOps/SRE |
| SRE | Provides strong data for SLOs and incidents | Linux & networking → SRE basics → MOE → Advanced SRE/Chaos |
| Platform Engineer | Standardizes telemetry on shared platforms | Cloud & Kubernetes → MOE → Service mesh / platform specialization |
| Cloud Engineer | Ensures cloud services are observable | Cloud associate/pro → MOE → Multi‑cloud or security specialization |
| Security Engineer | Gives runtime and threat visibility | Security basics → DevSecOps → MOE → Cloud security / AIOps |
| Data Engineer | Tracks pipeline and data platform health | Data engineering basics → MOE → Streaming / real‑time analytics |
| FinOps Practitioner | Connects observability to cost management | FinOps basics → MOE → Advanced FinOps |
| Engineering Manager | Guides observability strategy for teams | Engg background → Leadership → MOE → SRE / DevOps leadership |
Top Institutions for MOE Training
DevOpsSchool
- Official provider of the Master in Observability Engineering (MOE) certification.
- Offers structured classes, labs, and project‑based learning.
- Designed for working professionals with real‑world examples and scenarios.
Cotocus
- Provides deep DevOps and SRE training programs.
- Supports team‑based and corporate trainings with custom content.
- Focuses on practical projects so you can apply observability at work.
ScmGalaxy
- Delivers workshops on DevOps, CI/CD, and automation.
- Includes observability tools inside broader DevOps pipelines.
- Helps you understand how monitoring fits into end‑to‑end delivery.
BestDevOps
- Acts as a content and community hub for DevOps topics.
- Shares articles, case studies, and best practices on observability.
- Useful for staying updated after you finish MOE training.
devsecopsschool.com
- Focused on DevSecOps and secure software practices.
- Helps you use observability for security and compliance use cases.
- Good fit if you want to mix security and operations skills.
sreschool.com
- Specializes in Site Reliability Engineering (SRE).
- Connects observability concepts to SLOs, incidents, and SRE culture.
- Ideal if you want a strong reliability‑focused career.
aiopsschool.com
- Focused on AIOps and intelligent operations.
- Shows how to use telemetry data for automation and AI.
- Great next step if you want to build smart, self‑healing systems.
dataopsschool.com
- Teaches DataOps and data platform operations.
- Helps you apply observability to data pipelines and warehouses.
- Good path for Data Engineers who want stronger operations skills.
finopsschool.com
- Focused on cloud cost and FinOps practices.
- Connects observability usage to cloud spend and optimization.
- Useful if you want to manage both reliability and cost.
FAQs – Difficulty, Time, Value, Career
- Is MOE very difficult?
MOE is advanced but not impossible. If you understand DevOps or cloud basics, you can handle it with consistent study. The main challenge is joining many tools and ideas, not hard math. - How long should I prepare?
If you already work in operations or DevOps, 2–4 weeks of focused practice may be enough. If you are new to observability, plan for 6–8 weeks with more time on fundamentals and labs. - What are the main prerequisites?
You should know Linux commands, basic scripting, and core cloud concepts. It also helps if you have seen containers, Kubernetes, or microservices before, even at a basic level. - What is a good certification sequence including MOE?
A simple path is: DevOps or Cloud fundamentals → SRE basics → MOE → advanced SRE, AIOps, or security‑focused certifications. This gives you a strong base and then depth. - How does MOE help my career?
MOE proves that you understand how to design and run observability in real systems. Many companies now need this skill for SRE, DevOps, and platform roles, so it adds clear career value. - Which job roles can I target after MOE?
You can target roles such as Observability Engineer, SRE, DevOps Engineer, Platform Engineer, and Monitoring Lead. Over time, you can grow into Reliability Architect or Operations Architect. - Does MOE cover tools or only concepts?
MOE covers both. You learn key concepts and also work with tools like Prometheus, Grafana, ELK, and Jaeger. This mix helps you move from theory to real practice. - Is MOE useful if I am a manager?
Yes, because it gives you a clear view of what good observability looks like. You can then set better goals, review dashboards meaningfully, and support your team’s reliability work. - How is MOE different from SRE training?
SRE training focuses on rules and practices around reliability, like SLOs and incident reviews. MOE focuses on the data and tooling that make those practices possible and powerful. - Can MOE help me move into AIOps or MLOps?
Yes. AIOps tools need clean and rich telemetry data, which MOE teaches you to build. With MOE plus AIOps/MLOps knowledge, you can work on advanced, intelligent operations projects. - Is observability only for big companies?
No. Even small startups benefit from strong observability because it reduces outage time and speeds up debugging. The same principles scale from small to large systems. - How does MOE support long‑term growth?
Observability is a core, long‑lasting skill across many roles and technologies. With MOE, you can stay relevant as tools change, and you can move into senior technical or leadership positions more easily.
FAQs – Focused on MOE
- What topics are covered in MOE?
MOE covers observability basics, metrics, logs, traces, tools, OpenTelemetry, alerting, incident handling, and design patterns. It also includes advanced topics like cost and performance. - Is MOE vendor‑neutral?
MOE teaches general concepts that work across vendors. At the same time, it uses popular open‑source and cloud tools for hands‑on practice, so you are ready for real jobs. - Do I need prior experience with monitoring tools?
It is helpful, but not required. The course starts with basics and then moves into practice, so motivated beginners with some DevOps or cloud background can still learn well. - Does MOE include real labs and projects?
Yes. You get labs, demos, and project‑style work where you set up observability, build dashboards, and handle sample incidents. This helps you learn by doing, not just reading. - Is MOE useful if I mainly work with Kubernetes?
Yes, very much. Observability for Kubernetes and microservices is a major part of the program. You will learn how to track pods, services, and mesh traffic. - Is MOE recognized in the industry?
It comes from a known DevOps training provider that works with many professionals. While every company values certifications differently, the skills you gain are directly useful in real jobs. - Will MOE make me better at incident response?
Yes. You learn how to design alerts, read observability data quickly, and perform root cause analysis. This makes you more effective during outages and on‑call shifts. - Why should I do MOE now?
Many companies are moving fast to cloud‑native and microservices systems. Doing MOE now puts you ahead in a growing field where skilled people are in short supply.
Conclusion
Master in Observability Engineering (MOE) is a powerful and practical certification for engineers and managers who care about reliability and clear visibility. It teaches you how to design telemetry, use tools, and connect observability with SRE, DevOps, security, and cost. With MOE, you can move into high‑impact roles like Observability Engineer, SRE, Platform Engineer, or Reliability Architect and build a strong, future‑ready career.